Herramientas DevOps con IA integrada que uso en mi flujo diario
Después de un año midiendo cuáles de las herramientas DevOps con IA integradas realmente aportan y cuáles son humo, este es el stack que se queda en mi flujo diario.
Etiqueta
Después de un año midiendo cuáles de las herramientas DevOps con IA integradas realmente aportan y cuáles son humo, este es el stack que se queda en mi flujo diario.
Los agentes fallan. La pregunta no es si, sino cómo y qué haces en los primeros veinte minutos. Este es el runbook que distingue un incidente contenido de una reputación dañada.
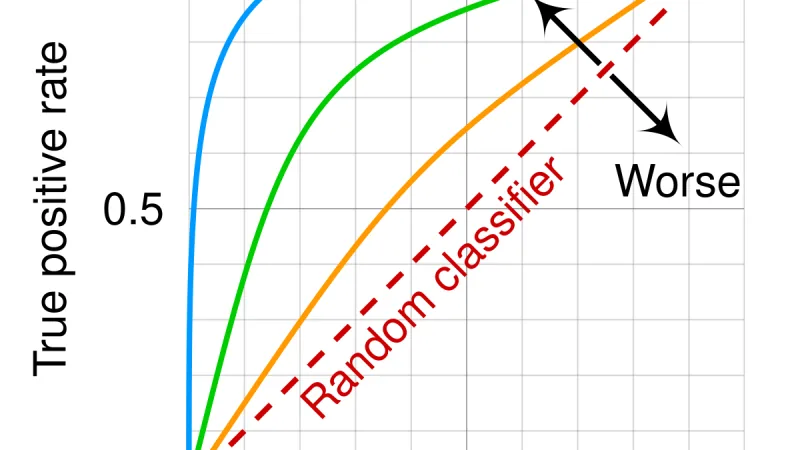
Después de año y medio llenando tableros con agentes en producción, la pregunta que separa equipos que envían fiable de los que van a ciegas sigue siendo la misma: ¿cómo mides que el agente está funcionando?
Una selección de postmortems publicados entre 2025 y 2026 por equipos que operan sistemas con IA en producción revela patrones repetidos: fallos en guardrails, deriva silenciosa de modelos, dependencia oculta del proveedor y una colección de sustos que vale la pena destilar.
Los cuadros de mando con IA llevan un par de años prometiendo detección de anomalías mágica y causa raíz automática. La realidad es más modesta pero también más útil, si se sabe separar el ruido del valor real. Repaso honesto de qué funciona y qué no.
Tras una década de Prometheus, tres años de consolidación alrededor de OpenTelemetry y la madurez definitiva del stack abierto con Grafana, Loki y Tempo, recomendaciones concretas para equipos que arrancan o revisan su capa de observabilidad. Qué encaja, qué sobra y qué evitar.
Los agentes que encadenan llamadas a modelos, herramientas y memoria son difíciles de depurar sin una instrumentación pensada para ellos. Después de un año largo operando agentes en producción, repaso qué hay que medir primero, qué estándares están consolidándose y qué errores caros evita tener trazas bien hechas desde el inicio.
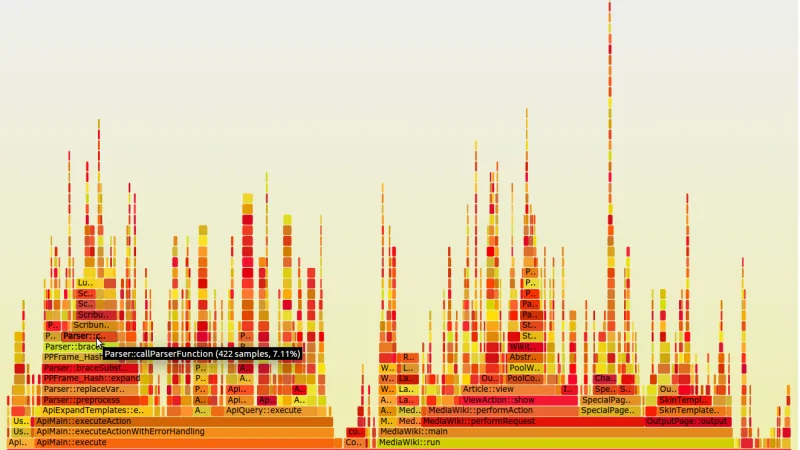
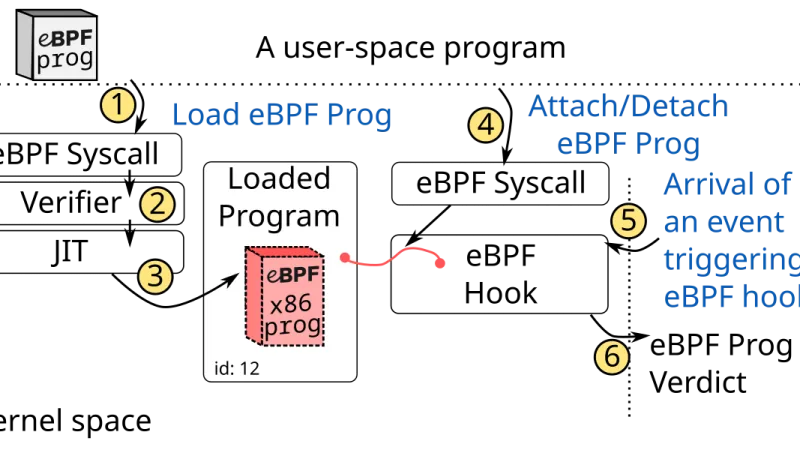
La combinación de Parca para perfiles continuos, Beyla para auto-instrumentación vía eBPF y Grafana como capa de visualización ofrece observabilidad profunda sin tocar código. Repaso a cómo encajan y dónde se sufren los límites.
El profiling continuo ha salido del terreno experimental y se ha vuelto una herramienta habitual en sistemas con tráfico real. Repaso qué aporta eBPF frente a instrumentación clásica, qué cuesta y cuándo compensa instalarlo.
Han pasado siete años desde que Google publicó el Workbook, y buena parte del libro no ha envejecido. Repaso los patrones que de verdad aplicamos en equipos pequeños y los que resultaron ser cultura de campus.
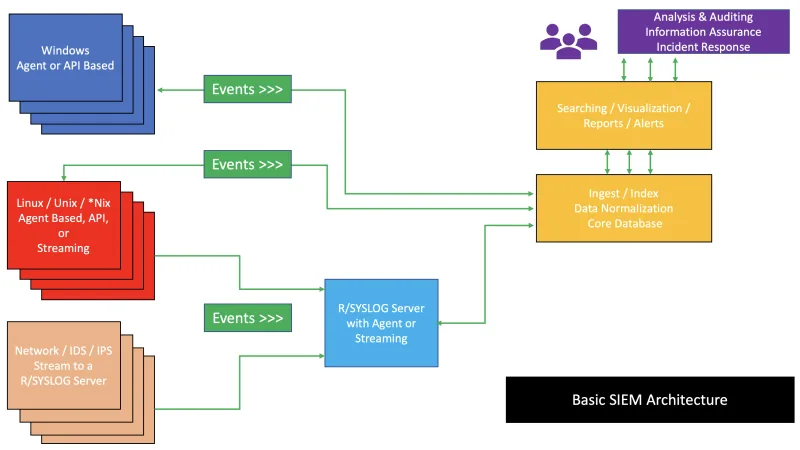
Dos años después de que Zero Trust dejase de ser palabra de marketing, toca mirar cómo conecta con el SIEM del día a día. Reflexión sobre señales útiles, ruido evitable y decisiones que de verdad cambian la postura de seguridad.
Profiling 24/7 en todo el clúster sin instrumentar aplicaciones. Parca, Grafana Beyla y Pyroscope conforman el stack moderno de observabilidad de rendimiento.