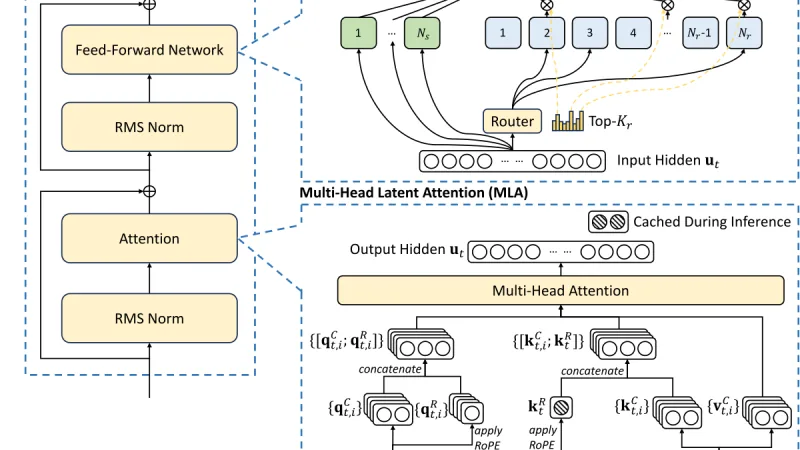
Frameworks de evaluación para retrieval: Ragas y similares
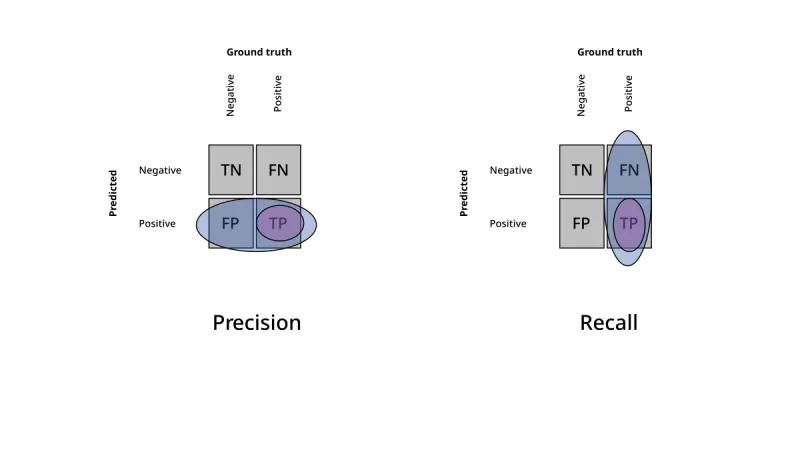
Evaluar RAG sin métricas es intuición. Ragas, TruLens y similares cuantifican faithfulness, relevance y correctness. Cómo integrar sin drama.
Categoría
Inteligencia artificial sin hype: modelos, agentes y casos de uso que funcionan en producción.
Evaluar RAG sin métricas es intuición. Ragas, TruLens y similares cuantifican faithfulness, relevance y correctness. Cómo integrar sin drama.
SGLang añade un DSL para controlar la generación de LLM con decoding restringido, branching y caché de prefijos. Cuándo supera a vLLM y por qué RadixAttention cambia la aritmética.
OpenAI presentó GPT-4o con texto, audio y visión integrados nativamente. Qué cambia en aplicaciones, latencia y precio frente a GPT-4 Turbo.
Llama 3 en 8B y 70B llevó a Meta a competir con frontier cerrados. Qué mejora sobre Llama 2, benchmarks clave y cuándo usarlo.
Nomic liberó un modelo de embeddings con pesos, datos y código abiertos que rivaliza con text-embedding-3-small de OpenAI. Por qué importa y dónde encaja.
LangGraph modela agentes LLM como grafos de estados explícitos. Cuándo supera al bucle tradicional de LangChain y cómo estructurar flujos que no se desmoronan en producción.
Outlines, Guidance e Instructor obligan al modelo a emitir JSON válido en el propio paso de generación. Cuándo ganan frente a reintentos y function calling.
Anthropic lanzó tres modelos Claude 3 el mismo día. Qué diferencia entre Haiku, Sonnet y Opus, cuándo elegir cada uno y cómo encajan con OpenAI.
Mistral liberó Mixtral 8x22B por magnet link sin fanfarria. Qué aporta técnicamente, cómo se compara con 8x7B y GPT-4, y qué hardware necesita.
LM Studio convierte cualquier portátil moderno en laboratorio de LLMs locales. Para quién es y cuándo supera a Ollama u OpenWebUI.
Un modelo, muchos destinos. ONNX Runtime resuelve la fragmentación de runtimes ML a costa de ceder algo de techo en cada plataforma concreta.
Cuando una aplicación habla con dos o más proveedores de LLM, antes o después aparece un proxy entre medias. LiteLLM propone uno concreto, y esta es la lectura honesta de qué gana y qué cuesta.