SGLang: control fino sobre la ejecución de LLM

Actualizado: 2026-07-07
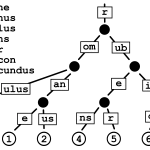
SGLang[1] (Structured Generation Language) apareció a principios de 2024 como alternativa a vLLM y TGI en la capa de inferencia de modelos de lenguaje, pero su ambición va más allá de servir tokens rápido. Propone un pequeño lenguaje embebido en Python para describir programas sobre LLM, con branching explícito, decoding restringido y reutilización agresiva del caché. Su aportación diferencial es RadixAttention: una estructura de datos que indexa el KV-cache en un trie radix para que peticiones distintas compartan prefijos sin recomputarlos.
La pregunta interesante no es si SGLang es mejor que vLLM en abstracto (no lo es), sino en qué cargas de trabajo su modelo de ejecución paga dividendos.
Puntos clave
-
RadixAttention indexa el KV-cache como un trie radix: prefijos compartidos se computan una sola vez.
-
En cargas con prefijos compartidos largos (system prompts de miles de tokens, few-shot, RAG repetitivo), los speedups frente a vLLM se sitúan entre 3 y 5 veces.
-
El DSL permite branching paralelo y constrained decoding sin round-trips HTTP.
-
Donde el prefijo compartido no existe, SGLang se comporta similar a vLLM con overhead adicional.
-
Para un chatbot básico tras API pública, vLLM sigue siendo el default correcto.
El problema que realmente resuelve
Un servidor como vLLM está optimizado para muchas peticiones heterogéneas, independientes, que entran por HTTP y se resuelven con continuous batching y PagedAttention. Ese diseño es excelente cuando los usuarios envían prompts disimilares entre sí.
Pero buena parte del tráfico moderno sobre LLM no tiene esa forma:
-
Los agentes multi-step reutilizan un system prompt de miles de tokens en cada iteración del bucle.
-
Los pipelines few-shot anteponen los mismos ejemplos a cada consulta.
-
Los chatbots con memoria acumulan contexto que crece a lo largo de la sesión pero cambia solo al final.
-
Un flujo RAG añade documentos recuperados que, por construcción, se repiten entre usuarios.
En todos estos casos, el prefijo compartido no es una curiosidad, es la mayoría del prompt. Recomputar el KV para esos tokens cada vez es trabajo tirado a la basura.
RadixAttention como propuesta de valor
La idea es conceptualmente simple. Cuando varias peticiones comparten un prefijo, sus vectores K y V para esos tokens son idénticos por construcción. Un trie (árbol radix) indexado por tokens permite encontrar en tiempo logarítmico el sufijo de caché más largo reutilizable y continuar la generación desde ahí.
La consecuencia práctica: el coste amortizado de un prefijo de diez mil tokens compartido por cien peticiones se acerca al coste de generarlo una vez. En cargas como agent loops, evaluación de benchmarks donde todos los items comparten la misma plantilla, o tool-calling iterativo, los speedups reportados frente a vLLM se sitúan entre 3 y 5 veces. No son números de marketing: salen de que efectivamente hay trabajo que ya no se hace.
El paper original de SGLang[2] (arXiv:2312.07104, diciembre de 2023) reporta hasta 6,4 veces más throughput que otros sistemas de inferencia en tareas de agentes, razonamiento y RAG. El anuncio de LMSYS Org[3] del 17 de enero de 2024 concreta esa cifra frente a vLLM 0.2.5, Guidance 0.1.8 y TGI 1.3.0: hasta 5 veces más throughput, medido sobre Llama-7B (1 GPU A10G de 24 GB) y Mixtral-8x7B (8 GPUs A10G) en nueve cargas de trabajo distintas, entre ellas MMLU, HellaSwag, extracción JSON y RAG con DSPy.
Donde el prefijo compartido no existe, RadixAttention degenera en cachés individuales y SGLang se comporta de forma similar a vLLM con overhead adicional por la maquinaria extra.
El DSL y por qué importa
El otro componente es el lenguaje. SGLang embebe en Python un conjunto de primitivas (gen, select, fork, user, assistant) que el runtime interpreta con conocimiento de la semántica. No es solo azúcar sintáctico: permite que el scheduler vea el grafo de dependencias del programa y decida qué ejecutar en paralelo.
Un programa típico encadena turnos, bifurca la generación en ramas paralelas y aplica restricciones por regex o gramática:
import sglang as sgl
@sgl.function
def analiza(s, tema):
s += sgl.system("Analista técnico conciso.")
s += sgl.user(f"Analiza {tema} en tres ejes.")
forks = s.fork(3)
forks[0] += "Pros: " + sgl.gen("pros", max_tokens=200)
forks[1] += "Contras: " + sgl.gen("contras", max_tokens=200)
forks[2] += "Coste: " + sgl.gen("coste", max_tokens=200)
forks.join()
s += sgl.user("Dame un veredicto JSON.")
s += sgl.gen("veredicto", regex=r'{"decision":"(si|no)","motivo":"[^"]{10,200}"}')
runtime = sgl.Runtime(model_path="meta-llama/Meta-Llama-3-8B-Instruct")
sgl.set_default_backend(runtime)
estado = analiza.run(tema="migrar a Kubernetes")El scheduler lanza las tres ramas en paralelo compartiendo el prefijo del system y del user inicial (eso lo resuelve el trie), y la restricción por regex del veredicto se compila a una máquina de estados que filtra logits en cada paso. Todo sucede dentro del mismo proceso, sin ida y vuelta HTTP. Ver también LangGraph para orchestración de agentes cuando el problema requiere gestión de estado entre pasos.
El constrained decoding
SGLang integra decoding restringido similar a librerías como Outlines: se construye un autómata que reconoce la gramática deseada y en cada paso del muestreo se anulan los logits de los tokens que llevarían a un estado inválido. La salida es válida por construcción, no por esperanza. Cuando necesitas JSON extraíble sin parser defensivo o respuestas que cumplan un formato estricto, vale la pena. Para evaluar la calidad de los outputs RAG estructurados, ver frameworks de evaluación para retrieval.
SGLang frente a vLLM
| Aspecto | vLLM | SGLang |
|---|---|---|
| Caso de uso principal | Servicio genérico, API-compatible | Cargas con prefijos compartidos largos |
| Prefix caching | Básico | RadixAttention (central) |
| DSL | No | Sí (Python embebido) |
| Madurez | Alta | Media-alta |
| Catálogo de modelos | Amplio | Menor |
| Curva de aprendizaje | Muy baja (API OpenAI) | Media |
vLLM sigue siendo la elección razonable para un servicio de inferencia genérico. SGLang entra cuando el problema cambia de forma: cuando quien orquesta la generación y quien la sirve son la misma pieza.
Limitaciones honestas
SGLang es más joven, su API cambia entre releases, el catálogo de modelos con kernels optimizados es menor y la documentación es la que cabe esperar de un proyecto en esa fase. El runtime consume una GPU con CUDA igual que vLLM. Y el DSL, por elegante que sea, añade una capa que el equipo tiene que aprender y el código tiene que depender.
Conclusión
SGLang merece atención seria si tu carga de trabajo tiene prefijos compartidos largos, branching paralelo o necesidad de output estructurado con validación en tiempo de generación. En esos casos el beneficio no es marginal: es la diferencia entre una GPU ocupada en recomputar el mismo system prompt mil veces o ocupada en generar tokens nuevos. Si tu carga no tiene esa forma, vLLM seguirá siendo el default correcto y SGLang será una herramienta que conviene conocer para cuando el problema sí encaje.
Este artículo también está disponible en inglés: SGLang: Fine Control Over LLM Execution.


