Code review asistido por IA: adopción honesta
Actualizado: 2026-07-07
A comienzos de 2023 empezamos a experimentar con revisiones de código asistidas por IA en el equipo. Primero con un bot que comentaba pull requests usando GPT-3.5, luego con integraciones más sofisticadas: Copilot para Pull Requests, CodeRabbit, y herramientas específicas como Qodo. Dos años después, las costumbres se han asentado y tengo opiniones razonablemente firmes sobre qué funciona y qué no.
Este no es un repaso de productos ni una lista de mejores herramientas. Es el balance que me habría gustado leer al empezar: dónde la IA en code review aporta valor real y dónde solo añade ruido que el equipo tiene que filtrar.
Puntos clave
-
La IA cubre bien los olvidos mecánicos (imports sin uso, TODOs huérfanos, docstrings desactualizadas) con más contexto que un linter tradicional.
-
Los resúmenes automáticos de PR reducen la fricción para revisores sin contexto previo.
-
Los falsos positivos en bugs sutiles son altos (≈80%); filtrarlos cuesta tiempo real.
-
No bloquear el merge por comentarios automáticos es la decisión que más impacto ha tenido en nuestro equipo.
-
Una sola herramienta, configurada bien, rinde más que tres bots solapándose.
Lo que esperábamos
La expectativa inicial era que la IA acabaría sustituyendo la primera vuelta de revisión humana. Los revisores pasan mucho tiempo señalando cosas de estilo, olvidos obvios, errores triviales. Si una herramienta pudiera cubrir todo eso automáticamente, el tiempo humano se podría dedicar a arquitectura y criterio.
Lo que ha pasado en la práctica es parcialmente eso y parcialmente otra cosa distinta.
Lo que ha funcionado
La IA es útil para detectar varios patrones muy concretos:
-
Olvidos mecánicos: un
TODOsin referencia, un import añadido pero no usado, una variable declarada y nunca leída, un test modificado que ya no se ejecuta. Las herramientas LLM formulan el aviso en lenguaje natural con contexto, lo que lo hace mucho menos ignorable que un "unused import". En equipos grandes donde los linters se vuelven ruido de fondo, esto ayuda. -
Inconsistencias código-documentación: si cambias una función pero la docstring dice otra cosa, la IA lo pilla con bastante fiabilidad. Los humanos también, pero es el caso típico donde nos saltamos el detalle.
-
Resúmenes para el revisor: un resumen automático de qué hace el PR, generado del diff, es un punto de entrada razonable. Si el resumen no cuadra con lo que el PR hace, eso ya es una señal útil. GitHub, que ya acumula más de 60 millones de revisiones con Copilot, reporta que el 71% deja al menos un comentario accionable y que se queda callado en el 29% restante en lugar de forzar ruido; la media es de 5,1 comentarios por revisión, según su propio blog[1]. Esa cifra encaja con lo que vemos: cuando la herramienta habla, casi siempre merece la pena leerlo.
-
Tests sugeridos: las herramientas que proponen casos de test aportan un beneficio modesto pero consistente. No sustituyen al diseño pensado por humanos, pero recogen casos límite olvidados, especialmente en funciones con muchos parámetros.
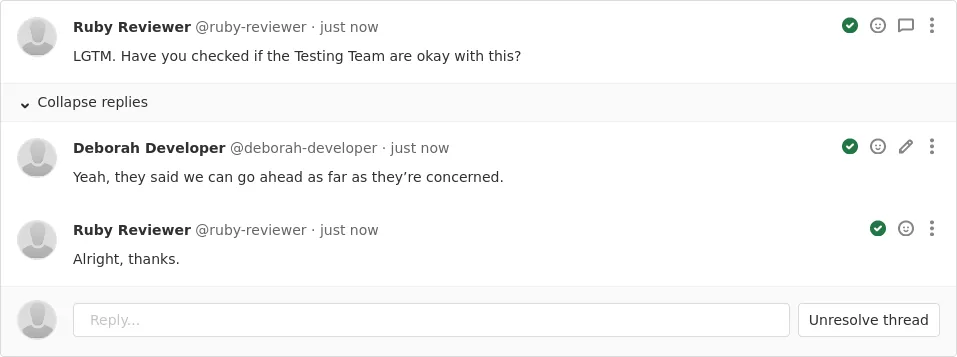
![]() Interfaz de GitHub mostrando comentarios automáticos en un pull request
Interfaz de GitHub mostrando comentarios automáticos en un pull request
Lo que no ha funcionado
En el lado contrario, hay varias cosas que hemos dejado de esperar:
-
Detección de bugs sutiles: cuando una herramienta dice «posible race condition» o «posible null dereference», la tasa de falsos positivos sigue siendo muy alta. Pronto descubrimos que el 80% eran imposibles en el contexto real. Hoy filtramos estos comentarios salvo cuando el código es claramente de riesgo. No somos los únicos con este problema: el benchmark independiente de Martian sobre casi 300.000 pull requests reales sitúa incluso a la herramienta líder, CodeRabbit, en un 49,2% de precisión, según su propio análisis del benchmark[2]. Dicho de otra forma: en el mejor caso publicado, alrededor de la mitad de los comentarios automáticos no llevan a un cambio real en el código.
-
Juicio arquitectónico: «esta función debería ser una clase», «este módulo debería estar en otro sitio». Sin entender el contexto del proyecto, se vuelven ruido permanente. La IA no sabe que esa función tiene un propósito deliberadamente limitado.
-
Revisiones de seguridad profundas: las herramientas detectan patrones obvios (credenciales hardcodeadas, SQL por concatenación), y eso es valioso. Pero no sustituyen una auditoría real. Un estudio académico reciente que evaluó Copilot Code Review contra una muestra etiquetada de vulnerabilidades conocidas encontró que la herramienta fallaba en detectar fallos críticos como inyección SQL y XSS con la fiabilidad que haría falta para confiar en ella como única barrera, según el paper de Amro y Alalfi[3]. Hemos visto casos parecidos: una herramienta aprueba un diff con un problema claro porque el patrón no encajaba con su entrenamiento.
El patrón que ha emergido
Después de probar varias configuraciones, el patrón que mejor ha funcionado es:
-
La IA hace una primera pasada automática al abrir el PR: resumen, olvidos mecánicos, tests no cubiertos, patrones de riesgo conocidos.
-
El autor del PR procesa esa pasada: arregla los olvidos, responde a las preguntas, descarta los falsos positivos con una nota breve.
-
El revisor humano se centra en lo que importa: arquitectura, trade-offs, coherencia con el sistema, legibilidad a largo plazo.
Un detalle importante: los comentarios de la IA no tienen autoridad de bloqueo en nuestro proceso. Son sugerencias explícitas. Nadie tiene que justificar por qué ignora un comentario automático.
Las decisiones que han hecho la diferencia
Hay tres decisiones concretas que marcan la diferencia entre equipos que integran bien la IA y los que la abandonan:
-
No exigir que todos los comentarios automáticos se resuelvan. Si haces eso, el ruido se vuelve insoportable en pocos meses.
-
Elegir una sola herramienta y usarla consistentemente. Tener tres bots comentando el mismo PR es contraproducente: se solapan, se contradicen y aumentan el coste cognitivo del revisor.
-
Revisar periódicamente qué tipo de comentarios aporta valor y ajustar la configuración. Casi todas permiten desactivar categorías o subir el umbral de confianza. Hemos silenciado varias categorías que generaban ruido.
Relacionado con esto, vale la pena comparar cómo la IA asiste también en el ciclo completo de desarrollo: desde la generación de código en el editor hasta la integración en CI/CD. Vemos ese ciclo extendido con más detalle en pair programming con IA. La calidad del código generado también mejora al combinar el asistente con dependencias bien mantenidas, como explica nuestra comparativa de Dependabot y Renovate.
Mirando adelante
Lo que veo venir es más de lo que ya funciona, pero mejor: resúmenes más precisos, detección más fiable de olvidos, integración con el histórico de incidencias para que un comentario pueda decir «este patrón es similar al que causó el incidente del trimestre pasado».
Lo que no espero es que la IA sustituya la revisión humana en decisiones arquitectónicas o en juicio de criterio. Esa parte se mantiene como trabajo humano, probablemente mejor asistida pero no delegada.
Mi consejo para quien piensa adoptar estas herramientas hoy es pragmático: empieza con una sola, configura desactivaciones agresivas, no bloquees el merge por comentarios automáticos, y revalúa cada seis meses si la herramienta aporta más de lo que cuesta mantener. Ese enfoque modesto es el que deja una mejora real sin haber perdido tiempo en promesas excesivas.
Este artículo también está disponible en inglés: AI-assisted code review: an honest adoption story.