Digital twins on the shop floor: the 2025 harvest
Actualizado: 2026-05-03
The digital twin has spent a decade being a word with lots of catalog and little factory. Today the picture has changed: real plants in Spain are running twins that serve a purpose, and the platforms making it possible have stopped changing daily. This post makes an honest review of the state of the art, filtered through the perspective of someone who has been on the shop floor seeing what holds and what doesn’t.
The analysis complements prior work in this series on IoT sensors and shop floor automation, predictive maintenance with ML, and digital twins in energy. For the broader Industry 4.0 context, the post on the digital industrial revolution provides the conceptual framework.
Key takeaways
- Three typologies have demonstrated return: the process twin for continuous optimization, the asset twin for predictive maintenance, and the plant twin for layout or production change simulation.
- The product twin (replica of the fabricated item’s behavior) remains more promising than real in most plants.
- Platforms that have established position: Siemens MindSphere/Xcelerator, PTC ThingWorx, Azure Digital Twins, and AWS IoT TwinMaker.
- The most common mistake is building the twin before having the data infrastructure (connected sensors, OPC-UA, historization).
- Industrial SMEs can implement useful twins in six to twelve months by starting with the asset twin, not the plant twin.
Typologies that have taken hold
After a decade of promises, four typologies have demonstrated measurable return in real industrial plants. Two have the most adoption; two are maturing more slowly.
Asset twin. Digital replica of a specific machine or equipment: its real-time state, operation history, configuration parameters, alarms, and predictive alerts. The most adopted typology in the plants I’ve visited, with the clearest ROI: early detection of failures before they cause unplanned downtime. Typical integration is OPC-UA from the equipment, historization in a SCADA or historian, and an analytics layer applying condition models or ML over time series.
Process twin. Replica of the complete manufacturing process: cycle times, efficiency of each station, bottlenecks, quality parameters. Used for continuous process optimization and for simulating the impact of changes (new operation sequence, batch change, new product introduction) before applying them. Return is in reduced changeover time, improved OEE, and reduced rejects.
Plant twin. Digital replica of the full plant, used primarily for scenario simulation: line reconfiguration, capacity planning, material flow simulation. Most used for investment decisions (justifying machine purchase, evaluating adding a shift) and for training shop floor personnel in a safe environment.
Product twin. Replica of product behavior throughout its lifecycle, tracking how a specific manufactured item was produced and how it behaves in the field. Has the greatest potential (complete traceability, field twin, quality as-built vs. as-designed) but requires the most mature traceability infrastructure. In practice, few plants outside aerospace and medical have implemented it in full.
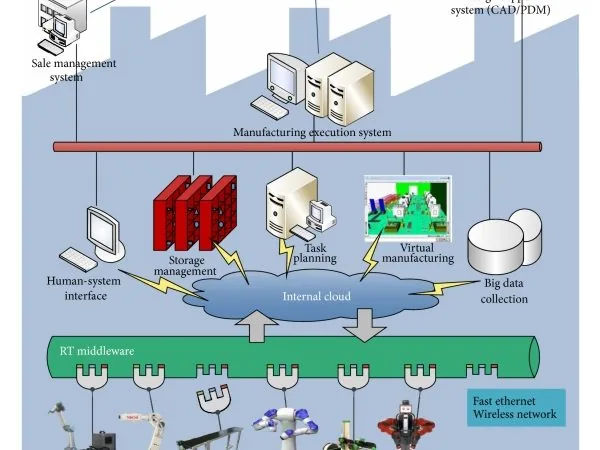
Platforms that have established position
The industrial digital twin platform market consolidated over the last two years. No longer a dozen startups trying to define the standard; four or five platforms with real installed bases.
Siemens Xcelerator / MindSphere. The default option in plants with Siemens equipment and Siemens automation environment. Native integration with TIA Portal, S7, and SIMATIC significantly reduces integration friction. If you already have Siemens in your plant, this is the most natural platform.
PTC ThingWorx + Vuforia. Strong in plants with many field assets and need for on-floor user experience (AR for maintenance, twin visualization on tablet next to the machine). ThingWorx has a wide connector ecosystem and is the most used platform by independent integrators in Spain and Europe.
Azure Digital Twins. Microsoft’s cloud-native option, strong in companies with a clear Microsoft commitment and need to integrate the twin with the corporate data ecosystem (Power BI, Synapse). Azure Digital Twins’ graph model is powerful for plants with many relationships between assets.
AWS IoT TwinMaker. The equivalent option in the AWS ecosystem, with native integration with IoT Core, S3 for historization, and SageMaker for ML. Less penetration in Europe than Azure for this use case, but more resources for plants already with a data architecture in AWS.
Choosing between these platforms matters less than the data infrastructure feeding them. A digital twin on the world’s best platform, fed with low-quality or high-latency data, has limited value.
Most common mistakes
Building the twin before having the data. The most costly mistake I’ve seen: investing in the digital twin platform without having sensors connected, OT/IT connectivity established, and historization running. The twin without data is a pretty interface with no content. Data infrastructure (sensors, connectivity, historization) is the prerequisite, not an implementation detail.
Starting with the most ambitious twin. Plants starting with “the full plant twin” almost always get stuck. The complexity of modeling the whole plant, integrating all equipment, and keeping the model synchronized is enormous. Projects that work start with a specific asset (the most critical machine, the most problematic line) and demonstrate value before scaling.
Not involving the shop floor operator from the design. The digital twin that the IT team designs without consulting the operator ends up being a tool nobody uses on the floor. Visualizations that make sense on a control room screen don’t make sense on a tablet next to a vibrating machine. The operator must be part of interface design and usage flow design.
Confusing SCADA with digital twin. A SCADA shows the plant’s current state; a digital twin can simulate future states, perform root cause analysis on historical data, and compare real state against the reference model. They’re complementary, not equivalent. A well-instrumented SCADA is the data source for the twin, not the twin itself.
What to expect in an industrial SME
Industrial SMEs have a different path than large plants. No digitalization department, limited budget, and technology must start paying in months, not years. The path that works for SMEs:
- Instrument the most critical assets with sensors (vibration, temperature, current) and OPC-UA connectivity. This step has standalone value, independent of the twin.
- Historize data in a system allowing time series queries. For SMEs, often self-hosted InfluxDB or TimescaleDB is sufficient.
- Build the asset twin of the most critical equipment, with condition alerts and real-time state visualization. The goal is to demonstrate ROI in failure prevention.
- Scale to more assets and, if the business justifies it, advance toward the process twin.
The full plant twin is rarely within reach of an SME without a specialized integrator, and in many cases isn’t necessary: a well-implemented asset twin can generate more value for an SME than a partially implemented, poorly maintained plant twin at a large company.
My read
The shop floor digital twin has matured from promise to tool with demonstrable ROI, but only in the right typologies and with adequate data infrastructure. The fantasy of the full-factory digital twin, updated in real time with perfect simulation of everything, remains just that: fantasy in most plants. What works is more modest and more useful: an asset twin that prevents failures, a process twin that reduces changeover time, a plant twin that simulates reconfiguration before moving a machine.
The gap between the catalog and the real plant has narrowed significantly. Teams starting now have mature platforms, integrators with real experience, and references in their own sector. The prerequisite remains the same as ten years ago: the data must exist before it can be modeled.