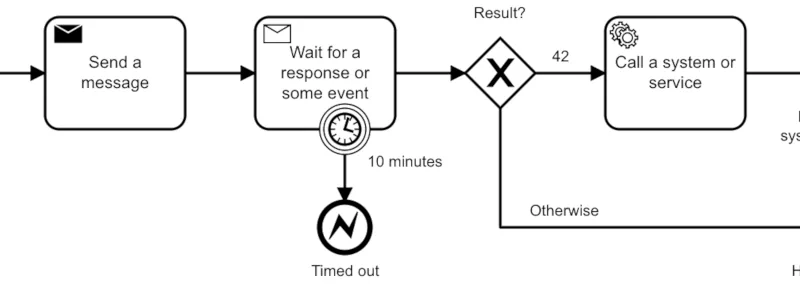
vLLM se ha convertido en la referencia para servir LLM en GPU. PagedAttention, batching continuo y API compatible con OpenAI. Cómo desplegarlo bien y cuándo compensa.
Litestream convierte SQLite en una base de datos con backup continuo a S3. Cómo funciona, setup típico y cuándo es mejor que Postgres para apps pequeñas.
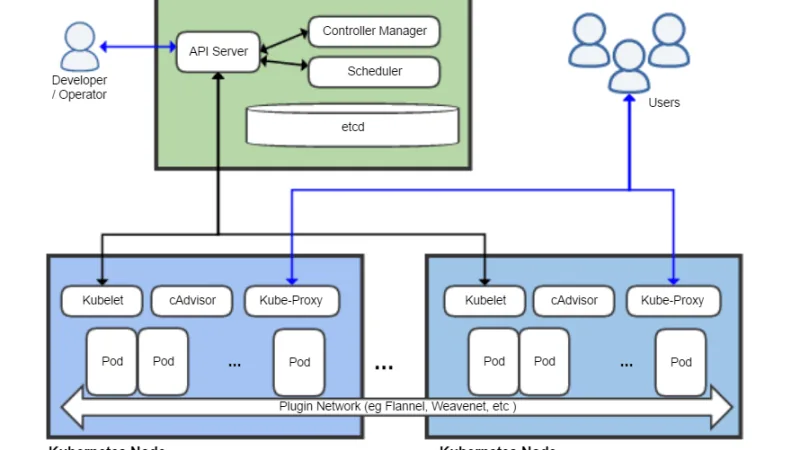
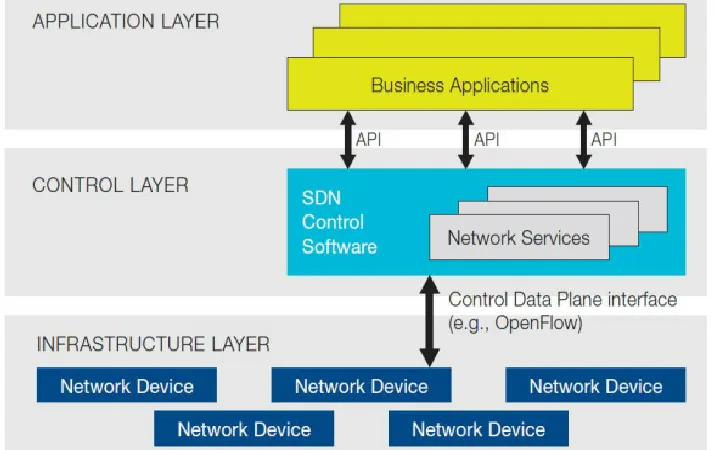
Kubernetes 1.31 no trae fuegos artificiales, pero estabiliza AppArmor, convierte los sidecars en ciudadanos de primera clase y deja DRA a un paso del GA. Repaso desde la óptica de quien opera clústeres.
OpenTelemetry declaró estables las señales de logs en julio de 2024. La tercera pata de la observabilidad moderna por fin se une a métricas y trazas bajo un único protocolo y un modelo de datos común.
Redis cambió a licencia dual en marzo de 2024. Valkey nació como fork BSD respaldado por AWS, Google y la Linux Foundation. Qué implica para usuarios y proyectos.
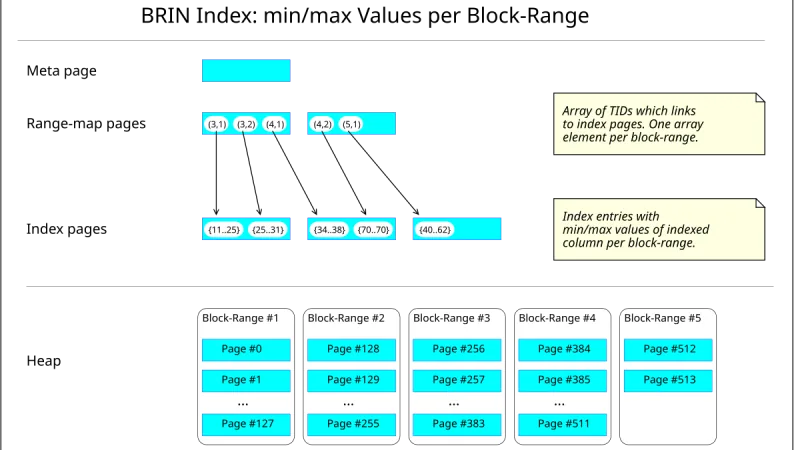
PG17 llega con vacuum más eficiente, logical replication con failover y JSON_TABLE estándar. Qué features valen la pena probar en staging y cómo planificar el upgrade.
PostgreSQL 16 cerró las brechas históricas de la replicación lógica. Parallel apply, slots en standby y bidireccionalidad disciplinada la convierten en herramienta de primera línea para migraciones y CDC.
SQLite en servidores es más viable de lo que crees. WAL, Litestream, LiteFS y patrones que hacen posible escalarla hasta donde muchos Postgres no llegan.
Linkerd apuesta por simplicidad y rendimiento antes que por catálogo de features. Dónde supera a Istio, qué cuesta operarlo y cuándo un service mesh compensa la complejidad.
Instalación reproducible de PostgreSQL 16 con pgvector en Debian o Ubuntu, con decisión razonada entre IVFFlat y HNSW y configuración lista para producción.
Internal Developer Platform es un término con tres grandes opciones. Cuál encaja mejor según el tamaño del equipo y la cultura de plataforma de tu organización.
SQLite y DuckDB comparten el modelo embedded pero resuelven problemas distintos. OLTP vs OLAP explicados con criterios prácticos para elegir y cuándo usarlas juntas.
containerd ejecuta los contenedores de la mayoría de clusters Kubernetes modernos, y casi nadie lo nota. Una lectura técnica de su arquitectura, su relación con Docker y qué cambia tras retirar el dockershim.
La arquitectura orientada a eventos desacopla servicios y mejora resiliencia. Cuándo aporta valor real, qué patrones funcionan y qué nuevos problemas trae.
eBPF permite ejecutar código seguro dentro del kernel para tracing, networking y seguridad. Por qué es la base de las herramientas modernas de observabilidad.
pgvector convierte PostgreSQL en una base vectorial competente. Por qué la búsqueda semántica necesita índices especializados y cuándo basta con extender Postgres.
Migrar de monolito a microservicios no es solo un cambio técnico: es una decisión organizativa con retos claros en interfaces, orquestación y cultura DevOps.