Clientes MCP en editores: la IA se integra donde ya trabajas

Índice de contenidos
- Puntos clave
- Por qué la integración en editor cambia la cosa
- VS Code como referencia
- Zed y el minimalismo funcional
- Cursor y la apuesta integrada
- Neovim y los forks comunitarios
- Qué servidores activo de forma estable
- Lo que no activo por defecto
- El problema de los permisos
- Cómo pensar la decisión
- Fuentes
Actualizado: 2026-07-07
El cambio silencioso de los últimos meses en el ecosistema de editores de código es que MCP ha dejado de ser algo que se consume desde una aplicación de chat aparte y ha empezado a estar integrado en el editor mismo. VS Code, Zed, Cursor y varios forks de Neovim tienen ya soporte nativo de cliente MCP, con lo cual el agente recibe el contexto del proyecto sin que el desarrollador tenga que copiar archivos a otra ventana. Este post recoge lo que he probado, qué servidores activo de forma estable, cuáles desactivo inmediatamente, y qué problemas prácticos han aparecido en el camino.
Para el contexto del protocolo MCP y cómo encaja en los flujos agénticos más amplios, el análisis de CI con agentes de IA describe cómo los mismos agentes se usan en pipelines. El post sobre seguridad de agentes LLM cubre las consideraciones de riesgo que aplican directamente a los servidores MCP. Los patrones de integración de agentes con herramientas de desarrollo se tratan en revisión de código con IA. Esta entrada también está publicada en inglés: MCP clients in editors: AI integrates where you already work.
Puntos clave
-
La integración MCP en editor elimina el ciclo de copiar código a otra ventana: el agente trabaja con vista completa del proyecto.
-
VS Code ofrece la implementación de cliente MCP más madura; Cursor baja la curva de entrada; Zed prioriza velocidad; Neovim requiere plugins comunitarios.
-
Los tres servidores que vale la pena activar de forma estable: filesystem acotado al workspace, git en solo lectura, documentación interna del proyecto.
-
El control de permisos dentro de MCP es rudimentario; la confianza en cada servidor depende de la reputación del autor, no de sandboxing real del cliente.
-
MCP se consolidará como estándar de integración de agentes en editores del mismo modo que LSP lo hizo para los servidores de lenguaje.
Por qué la integración en editor cambia la cosa
Hasta principios de 2025, la mayoría del uso serio de agentes ocurría en aplicaciones separadas: Claude Desktop, interfaces web, terminales dedicadas. El editor seguía siendo territorio del autocompletador clásico, con integraciones superficiales con IA que básicamente copiaban el archivo actual al modelo y devolvían sugerencias. MCP integrado cambia esto: el agente puede leer archivos, ejecutar comandos acotados, consultar el estado del repositorio y devolver resultados en el mismo entorno donde el desarrollador ya trabaja.
La ventaja práctica es enorme. Desaparece el ciclo de copiar código a otra ventana, explicar el contexto, recibir la respuesta y volver al editor. Todo ocurre en la misma superficie. La consecuencia menos obvia es que el agente ya no trabaja con fragmentos aislados sino con vista completa del proyecto, lo que mejora sensiblemente la calidad de las respuestas a preguntas estructurales.
VS Code como referencia
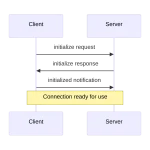
VS Code llega con la implementación de cliente MCP más madura que he probado hasta ahora. El soporte nativo llegó el 12 de junio de 2025 con cobertura de la especificación completa del protocolo (autorización, prompts, recursos y sampling), según el anuncio oficial del equipo de VS Code[1]. La configuración vive en un archivo del workspace que el editor relee al arrancar; cada servidor se define con su comando de arranque y sus permisos, y el editor los lanza como procesos hijos y gestiona la comunicación transparente al usuario.
Lo que ha sorprendido positivamente es que la integración no es intrusiva. Los servidores activos aparecen en una barra lateral dedicada, se pueden desactivar temporalmente sin editar archivos, y cada invocación del agente muestra claramente qué servidor respondió. Esta trazabilidad convierte MCP en algo observable en lugar de magia negra.
La limitación más molesta es que el editor no tiene todavía una buena forma de limitar el agente a ciertos servidores según el contexto. Si un servidor de filesystem tiene acceso al proyecto entero, no hay manera de decirle al agente «solo lee dentro de esta carpeta» sin editar la configuración global. Para proyectos con monorepo y partes sensibles, esto obliga a configuraciones más restrictivas de lo ideal.
Zed y el minimalismo funcional
Zed ha ido por otro camino, más minimalista. El soporte de MCP está en el editor pero la interfaz es austera: se configura por archivo, se activa un panel de agente, y los servidores responden con la misma filosofía de rapidez que caracteriza al editor. Por ahora cubre las capacidades Tools y Prompts del protocolo, no Recursos ni Sampling[2], y desde la versión 0.224.0 añadió controles de aprobación por herramienta. En proyectos grandes, esa rapidez se nota: la latencia entre que pides algo al agente y recibes la respuesta es menor que en VS Code.
La pega de Zed es que el ecosistema de extensiones es más pequeño y los servidores MCP populares tardan más en aparecer con integración de primera calidad. Para quien viva en Zed y le guste su filosofía, es una buena opción; para quien necesite soporte amplio de servidores, VS Code sigue ganando.
Cursor y la apuesta integrada
Cursor ha integrado MCP más temprano que nadie y ha invertido en hacer que la experiencia sea fluida desde el primer arranque. La configuración viene con valores por defecto sensatos, los servidores de filesystem y git están activados, y el agente tiene contexto del proyecto sin pedírselo. La configuración de proyecto se guarda en un archivo .cursor/mcp.json que solo aplica a ese repositorio, según su documentación[3]. Para quien venga de otro editor sin experiencia de MCP, Cursor baja la curva de aprendizaje de forma notable.
El coste de esa integración profunda es que Cursor opina sobre cómo se usa el agente. El flujo de trabajo está más cerrado que en VS Code, y ciertos patrones que son fáciles en otros editores son más tediosos. Es el clásico equilibrio entre facilidad y flexibilidad, y Cursor ha elegido facilidad.
Neovim y los forks comunitarios
El mundo Neovim llega más tarde y por vía de plugins de la comunidad. No hay soporte oficial de MCP en el upstream, pero hay al menos tres plugins activos que implementan cliente MCP con distintos niveles de integración. El que mejor funciona es mcphub.nvim[4], que integra MCP con el sistema de comandos propios de Neovim en lugar de crear una interfaz paralela; exige Neovim 0.8 o superior compilado con LuaJIT y Node.js 18 o superior.
La ventaja de Neovim es que la configuración es texto plano, versionable y portable. La desventaja es que los servidores MCP asumen ciertas convenciones de cliente que algunos plugins todavía no soportan bien. Para usuarios avanzados de Neovim, la experiencia es buena; para quienes quieran entrar a MCP desde cero, mejor empezar con VS Code o Cursor.
Qué servidores activo de forma estable
Independientemente del editor, hay un conjunto de servidores MCP que mantengo activos en casi todos los proyectos:
-
Filesystem acotado al workspace: acceso de lectura y escritura limitado al directorio del proyecto. Es el servidor básico que habilita casi todo lo demás.
-
Git, solo lectura: para que el agente pueda consultar el estado del repositorio, diffs e historial sin ejecutar comandos que modifiquen nada. La regla es clara: el agente puede leer, las escrituras las hace el desarrollador tras revisar la propuesta.
-
Documentación interna del proyecto: en varios repos mantengo un directorio con notas de arquitectura, convenciones y decisiones. Exponerlo al agente vía MCP le da acceso a ese conocimiento tácito sin tener que inyectarlo en cada prompt. Probablemente la integración que más valor aporta, porque convierte documentación muerta en contexto vivo.
Lo que no activo por defecto
Hay servidores que pruebo y acabo desactivando:
-
Shell con acceso libre: la comodidad de que el agente ejecute comandos no compensa el riesgo. Si un servidor propone ejecutar comandos arbitrarios en el sistema, lo restrinjo a un sandbox o lo elimino.
-
Búsqueda web general: añade ruido, devuelve resultados de calidad variable y el agente suele interpretarlos sin el juicio necesario.
-
Base de datos con acceso a producción: para desarrollo, con solo lectura y sobre copias, es útil; para producción, el riesgo de que el agente genere una consulta cara o bloqueante es demasiado alto.
El problema de los permisos
La pregunta práctica que más me hacen compañeros es cómo controlar qué puede hacer cada servidor. La respuesta honesta es que el control es más rudimentario de lo deseable. MCP define un modelo de capacidades por servidor pero la granularidad dentro de cada capacidad depende de la implementación concreta.
Esto significa que la confianza en cada servidor es un tema de reputación del autor, no de sandboxing real del cliente. Mi práctica: servidores oficiales o de autores conocidos se usan tal cual; servidores de la comunidad se revisan al menos por encima antes de instalarlos, especialmente si piden capacidades sensibles.
Cómo pensar la decisión
Si estás empezando con MCP en el editor, la recomendación es VS Code o Cursor con los tres servidores básicos y nada más. Añade el resto solo cuando una tarea concreta lo justifique, y quítalos cuando la tarea termine. Menos servidores activos es mejor contexto y menos superficie de riesgo.
Lo que creo que se va a consolidar pronto es que MCP se volverá la forma estándar de integrar agentes en editores, igual que LSP se volvió estándar para servidores de lenguaje. Cuando eso pase, la decisión de editor y la decisión de modelo se volverán ortogonales, y cada equipo podrá combinar lo que le convenga. Por ahora estamos en la fase de transición, donde los clientes aprenden el protocolo y los servidores buenos se separan de los experimentos efímeros.