Un sistema RAG sin evaluación continua se degrada en silencio. Los índices cambian, los modelos se actualizan, los usuarios preguntan cosas nuevas. Este es un repaso práctico de qué métricas vigilar y cómo montar el cuadro de mando que avisa antes del incidente.
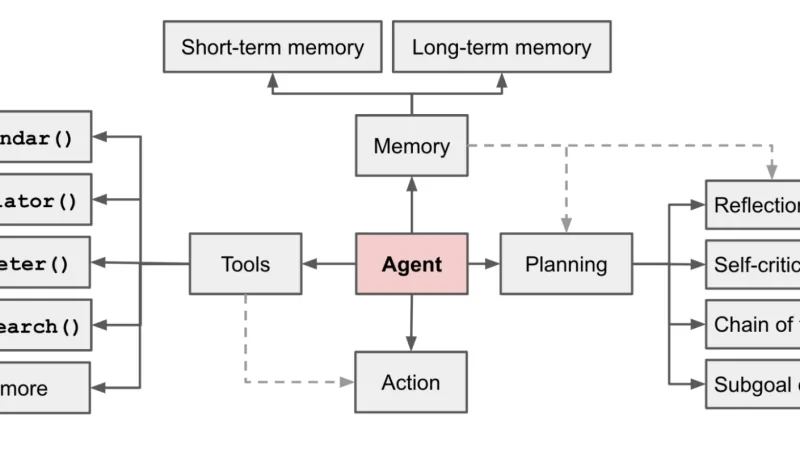
Los agentes de IA han pasado de ser un tema de laboratorio a tener SDKs serios en tres grandes proveedores. Reflexión sobre cómo pasar de la demo llamativa a un caso de uso interno que mueva una métrica real.
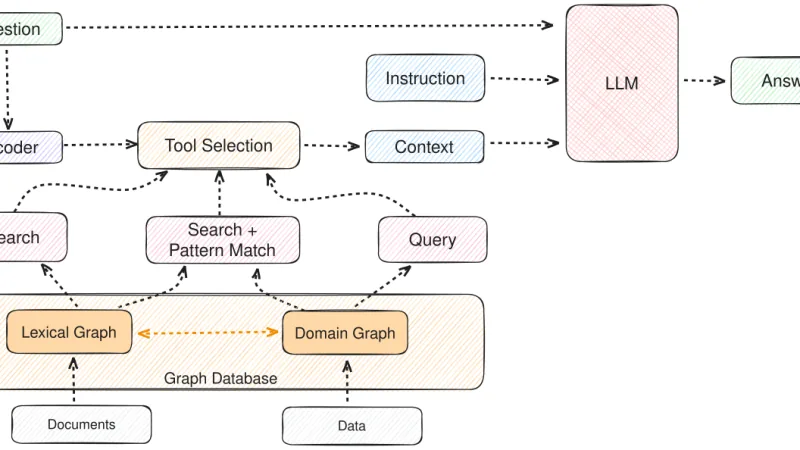
Desde que Microsoft abrió GraphRAG, el patrón de usar grafos sobre tus propios datos ha pasado de experimento académico a técnica con aplicaciones prácticas. Reflexión sobre cuándo compensa, cómo se monta y qué errores se repiten.
Anthropic publicó Claude 3.7 Sonnet a finales de febrero con pensamiento extendido opcional y un compañero de consola llamado Claude Code. Reflexión sobre qué cambia de verdad y qué queda para la próxima familia.
vLLM se ha consolidado como el motor de serving de LLM más adoptado en producción. Repaso de las mejoras recientes, qué cambia para quien lo opera y qué sigue siendo punto débil.
GraphRAG lleva un año en uso empresarial real. Balance de qué tipos de preguntas resuelve mejor que el RAG clásico, qué cuesta operarlo y cuándo la complejidad extra compensa.
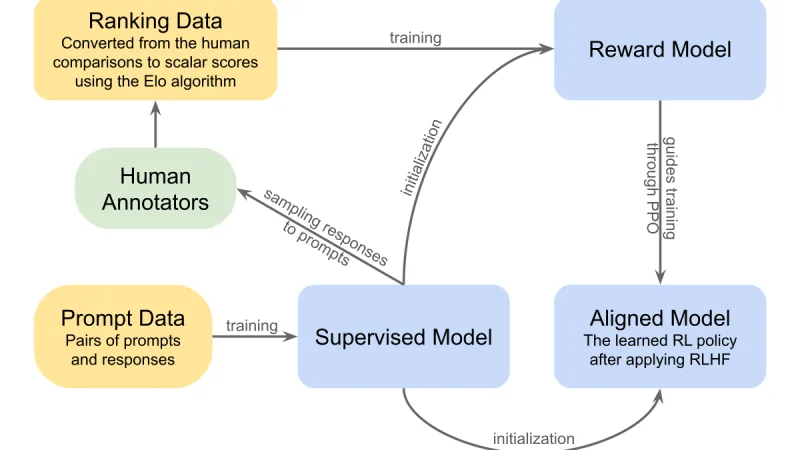
Tres años después de que RLHF se hiciera popular, el paisaje del alineamiento de modelos es más rico. Repaso de RLHF, DPO y los métodos más recientes como KTO o ORPO, con criterios para elegir.
Google publicó Gemma 2 a mediados de 2024 y ya lleva tiempo en uso real. Balance de cómo compite en el ecosistema de modelos abiertos, qué tamaños tienen sentido y dónde ha cuajado su adopción.
La serie o3 de OpenAI empieza a estar disponible y marca un cambio real en razonamiento complejo. Análisis de dónde brilla, dónde sigue fallando y qué cambia para quien construye productos con LLMs.
Google ha lanzado Gemini 2.0 con un énfasis claro en uso de herramientas y agentes. Repaso de qué aporta, dónde está por detrás de la competencia y en qué tipo de aplicaciones encaja mejor.
Los procesadores Copilot+ de Qualcomm, Intel y AMD han normalizado la presencia de una NPU en el PC doméstico. Qué cambia realmente para ejecutar modelos en local y cuándo merece la pena.
LoRA reduce el coste del fine-tuning de forma dramática. QLoRA va aún más allá combinando cuantización y adaptadores de bajo rango. Cómo funcionan, cuándo usarlos y qué calidad esperar.
Outlines, Guidance e Instructor obligan al modelo a emitir JSON válido en el propio paso de generación. Cuándo ganan frente a reintentos y function calling.
LangChain unifica la construcción de aplicaciones con LLM: prompts, retrievers, agentes y memoria. Cuándo ayuda y cuándo añade complejidad innecesaria.
Google lanzó Bard con PaLM 2 como respuesta directa a ChatGPT. Análisis de capacidades, comparativa con GPT-4 y estrategia de integración con su ecosistema.
Cerebras-GPT libera 7 modelos de lenguaje open-source entrenados sobre hardware especializado. Qué los diferencia, dónde descargarlos y para qué son útiles.
5 min289
Usamos cookies propias y de terceros para analizar el tráfico del sitio. Puedes aceptarlas, rechazarlas o configurar tu elección.
Más información
Preferencias de cookies
NecesariasImprescindibles para el funcionamiento del sitio. Siempre activas.
AnalíticasNos ayudan a entender cómo se usa el sitio (Google Analytics).