
How to install and tune oMLX on M5 Max 128 GB

Updated: 2026-06-20
oMLX is an LLM inference server built on MLX (the framework Apple shipped in December 2023 for Apple Silicon) with continuous batching, two-tier KV cache (RAM + SSD), and an OpenAI- and Anthropic-compatible API. On a Mac M5 Max with 128 GB of unified memory you can hold three or four large models at once with TurboQuant 3.5-bit on KV cache, enough to feed chat, agent and IDE in parallel. This guide collects the configuration tested in May 2026 to get the most out of that combination.
Quick answers
Which oMLX version do I use and how do I install it? Version 0.3.8 (released 30 April 2026, Apache 2.0). Easiest: download the .dmg from GitHub Releases[1], open it and drag to Applications. Or install via brew tap jundot/omlx https://github.com/jundot/omlx and brew install omlx. The first load of the panel at http://localhost:8000/admin prompts for the API key.
What TurboQuant setting makes sense on 128 GB? 3.5-bit. vLLM’s independent analysis published 11 May 2026[2] shows 3.5-bit matches full-precision quality with about 4x less KV-cache memory. On M5 Max that turns 128k context from “blows past available RAM” into “fits alongside other loaded models.”
Which models can I load concurrently on 128 GB? Primary: unsloth/Qwen3.6-35B-A3B-MLX-8bit (37.7 GB, MoE with 3B active). Fast helper: Qwen3-14B-Instruct-mlx-4bit (8 GB). Vision: Qwen2.5-VL-32B-mlx-4bit (18 GB). Embeddings: BGE-M3-mlx (1.2 GB). Reranker: ModernBERT-base-mlx (150 MB). Comfortable sum: ~65 GB with headroom.
How do I point Claude Code at the local endpoint? Export ANTHROPIC_BASE_URL=http://127.0.0.1:8000, ANTHROPIC_AUTH_TOKEN=<your_api_key> and the three ANTHROPIC_DEFAULT_*_MODEL variables (Opus/Sonnet/Haiku). Launch with claude --bare to drop the system prompt to ~1,795 tokens. The dashboard’s Claude Code with oMLX section assembles the full command for you.
Does this replace Claude Opus 4.7? Not one for one. Claude Code is tuned for Claude’s tool-use format; a non-Claude model behind the endpoint loses reliability in agentic loops. Use this for offline work, sensitive data that should not leave the Mac, or as a fallback when api.anthropic.com is rate-limiting you.
Install
The easiest path: download the .dmg from GitHub Releases[1], open it and drag the app to Applications. The server starts in the background with a menu-bar icon.
Or install via Homebrew:
brew tap jundot/omlx https://github.com/jundot/omlx
brew install omlx
omlx serve --model-dir ~/.mlx/models
The first hit to http://localhost:8000/admin prompts for the API key. By default oMLX ships with no API key set (empty field), which is fine for local testing. If the instance only listens on 127.0.0.1 this is safe; the moment you expose it to the LAN or plan to share the endpoint, go to Settings → Auth & Info and set a long random string. The section accepts multiple keys at once.

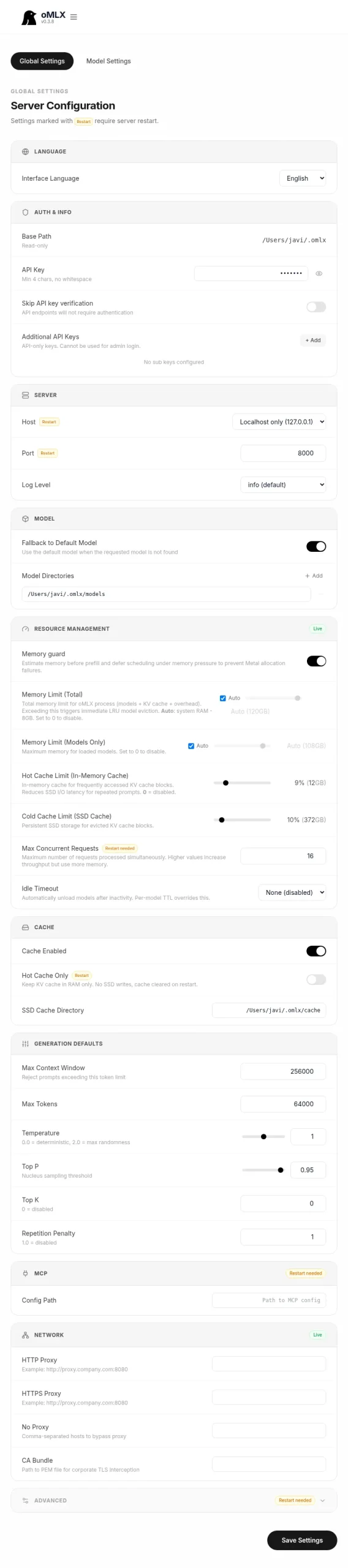
Server settings for 128 GB
Settings → Global Settings holds the full server configuration. The decisions that matter on a 128 GB machine:
- Server → Host:
Localhost only (127.0.0.1). If you open it to the LAN, put real auth in front first. - Server → Port:
8000by default. - Resource Management → Memory Limit (Total):
Auto. oMLX subtracts what macOS reserves; on 128 GB you end up around 110-114 GB for inference. - Resource Management → Memory Limit (Models Only):
Auto. Keeps a percentage for activations, KV cache and auxiliary processes. - Resource Management → Hot Cache Limit:
10%. Intermediate RAM-tier KV cache. With TurboQuant enabled on the models that support it (see below), 10% is the value people running this setup in practice land on for 128 GB; with TurboQuant off and a single model loaded you can drop to Off, but you stop gaining. - Resource Management → Cold Cache Limit (SSD Cache):
10%. Around 80 GB of SSD for cold tokens without saturating it. - Resource Management → Max Concurrent Requests:
16. Comfortable for a single user with an agent, a chat session and an IDE pinging at once. Raise to 32 if you share with a small team. - Resource Management → Idle Timeout:
None. Keeps models warm; first-token latency drops from several seconds to sub-second. - Generation Defaults → Max Context Window:
256000as the global default. The Qwen3.6 family holds up at long context, and with TurboQuant the effective RAM stretches enough to actually use it. Each model can be capped lower in Model Settings. - Generation Defaults → Max Tokens:
64000. Upper bound per response. Going higher only matters if you plan to generate full books in one shot. - Generation Defaults → Temperature:
1.0for general use,0.2-0.5for code models. - Model Settings → Experimental Features → TurboQuant KV Cache: enable at
3.5-biton the large dense models. vLLM’s independent study published 11 May 2026[2] of Google’s TurboQuant shows 3.5-bit matches full-precision quality with roughly 4x less KV-cache memory; on M5 Max it makes 128k context fit on models where FP16 does not.
Model stack for multi-LLM
With 128 GB you have room to load one large primary model, a fast helper, a VLM, embeddings and a reranker concurrently. Download them from Models → Downloader by pasting the Hugging Face repo URL.
The recommendation holding up in May 2026 comes from people actually running Claude Code on oMLX on M5 Max (see Diego R. Baquero’s gist[3] for the source): Unsloth’s Qwen 3.6 35B-A3B family in MoE with ~3B active parameters per token. On 128 GB the 8-bit fits without breaking a sweat:
- Primary (chat + code + reasoning):
unsloth/Qwen3.6-35B-A3B-MLX-8bit(~37.7 GB). MoE 35B with 3B active. The all-rounder: long chat, code, agents. On 128 GB it fits alongside everything else without squeezing. - More compressed alternative:
unsloth/Qwen3.6-35B-A3B-UD-MLX-4bit(~21.6 GB) if you want two primary models loaded at once. Loses a notch of quality versus 8-bit but leaves room to experiment. - Dense reasoning (when MoE falls short):
Mistral-Large-2-123B-Instruct-mlx-4bit(~70 GB) orLlama-3.3-70B-Instruct-mlx-4bit(~40 GB). For deep reasoning in a single pass, where a dense architecture beats a small-activation MoE. - Fast helper:
Qwen3-14B-Instruct-mlx-4bit(~8 GB). For cheap tasks in agents, parsing and summaries. - Vision:
Qwen2.5-VL-32B-Instruct-mlx-4bit(~18 GB) covers OCR, image description and multimodal reasoning. - Embeddings:
BGE-M3-mlx(~1.2 GB), dense + sparse + multi-vector in a single model. - Reranker:
ModernBERT-base-mlx(~150 MB) to close the loop on a decent RAG pipeline.
Comfortable concurrent load with Qwen3.6 35B-A3B 8-bit as primary + 14B helper + VL-32B + embeddings + reranker: around 65-70 GB. Add Mistral Large 2 123B on top for dense reasoning and you hit ~135 GB nominal, but the LRU policy moves idle models to SSD and the cohabitation works in practice for sessions that do not pin everything at once. Pin the primary model from Model Manager so it never gets evicted.
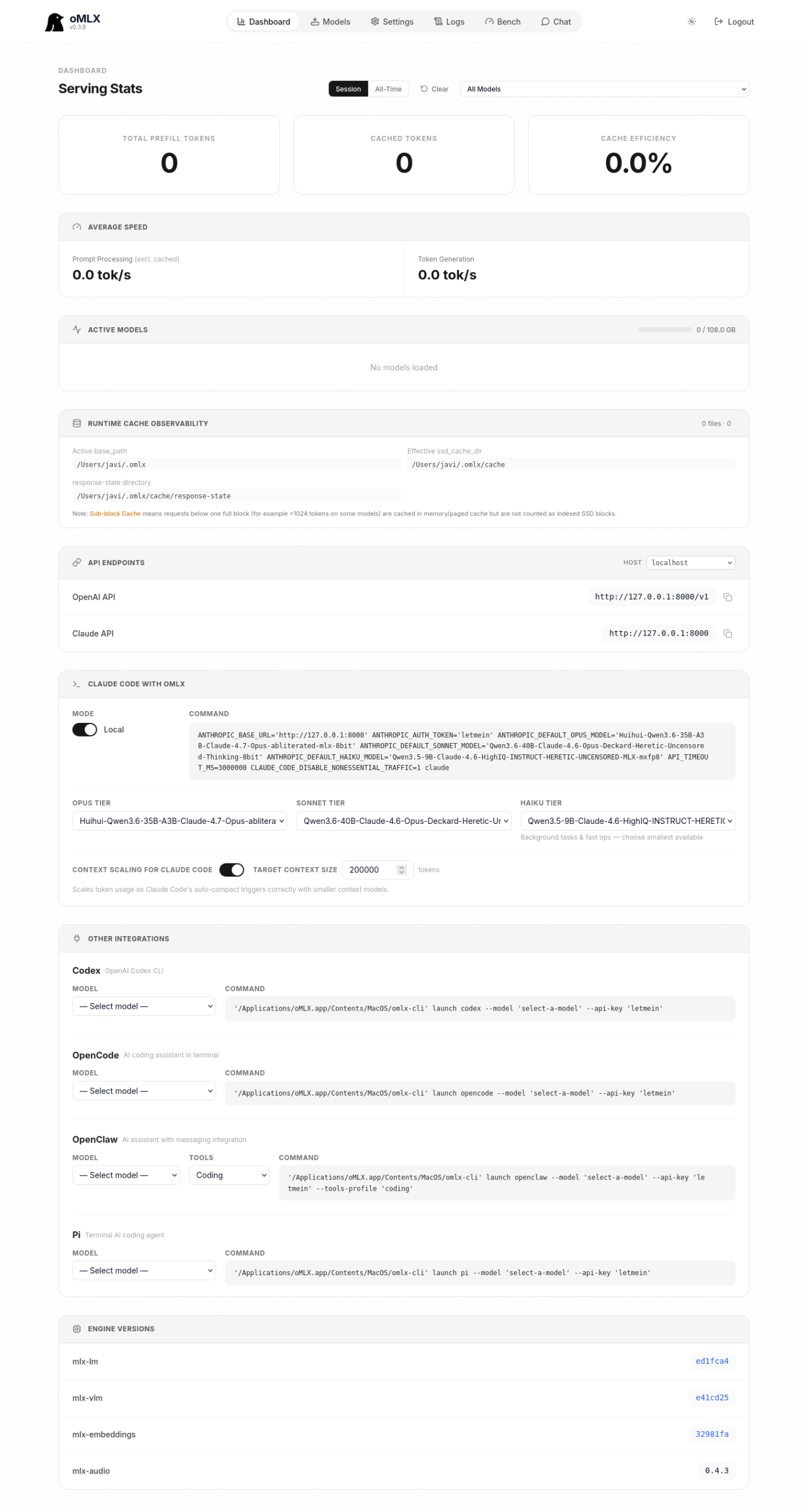
Point Claude Code at the local endpoint
oMLX exposes an Anthropic-compatible API at http://127.0.0.1:8000 (root, not /v1). Claude Code respects ANTHROPIC_BASE_URL, so pointing the CLI at your Mac is a matter of exporting environment variables. First, turn off the attribution header in Claude Code’s global config so the gateway does not bolt extra noise onto the prompt:
~/.claude/settings.json:
{
"env": {
"CLAUDE_CODE_ATTRIBUTION_HEADER": "0"
}
}
Then the startup command:
export ANTHROPIC_BASE_URL=http://127.0.0.1:8000
export ANTHROPIC_AUTH_TOKEN=<your_api_key>
export ANTHROPIC_DEFAULT_OPUS_MODEL=unsloth/Qwen3.6-35B-A3B-MLX-8bit
export ANTHROPIC_DEFAULT_SONNET_MODEL=unsloth/Qwen3.6-35B-A3B-MLX-8bit
export ANTHROPIC_DEFAULT_HAIKU_MODEL=Qwen3-14B-Instruct-mlx-4bit
export ANTHROPIC_DEFAULT_MODEL=unsloth/Qwen3.6-35B-A3B-MLX-8bit
export API_TIMEOUT_MS=600000
export CLAUDE_CODE_USE_BEDROCK=0
export DISABLE_NONESSENTIAL_TRAFFIC=1
claude --bare
The --bare flag skips hooks, LSP, plugin sync and auto-memory, dropping Claude Code’s system prompt to around 1,795 tokens (versus several thousand with everything loaded). For offline work against a local model that is the sensible default: every token in the system prompt is bandwidth your Mac would otherwise burn. Drop the flag when you point back at api.anthropic.com.
The oMLX dashboard builds this command for you in the Claude Code with oMLX section: pick Opus, Sonnet and Haiku from three dropdowns and copy the ready-to-paste command. Set Context scaling for Claude Code to 64000: Claude Code requests 200k tokens by default, but a local model behaves better with a 64k ask than a 200k ask it cannot honor. The option scales the reported counts so auto-compact triggers at the target size.
A real caveat: Claude Code is tuned to Claude’s tool-use format and response patterns. A non-Claude model behind ANTHROPIC_BASE_URL works for autocomplete and reasoning, but you will see drops in tool-call reliability and in agentic loops. Use this for offline work, sensitive data that should not leave the Mac, or as a fallback when api.anthropic.com is rate-limiting you. It is not a 1:1 substitute for Claude Opus 4.7.
SSH from another Mac
If oMLX runs on a Mac Studio and you want to use Claude Code from your MacBook, SSH port forwarding is the bridge:
ssh -L 8000:localhost:8000 user@mac-studio
Once connected, 127.0.0.1:8000 on your laptop points to the Studio’s oMLX. Save this script as claude-local.sh:
#!/bin/bash
export ANTHROPIC_BASE_URL='http://localhost:8000'
export ANTHROPIC_AUTH_TOKEN=''
export ANTHROPIC_DEFAULT_OPUS_MODEL='Qwen3.6-35B-A3B-MLX-8bit'
export ANTHROPIC_DEFAULT_SONNET_MODEL='Qwen3.6-35B-A3B-MLX-8bit'
export ANTHROPIC_DEFAULT_HAIKU_MODEL='Qwen3-14B-MLX-4bit'
export ANTHROPIC_DEFAULT_MODEL='Qwen3.6-35B-A3B-MLX-8bit'
export API_TIMEOUT_MS=600000
export CLAUDE_CODE_USE_BEDROCK=0
export CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1
claude --bare --dangerously-skip-permissions
Make it executable with chmod +x claude-local.sh and run it from the SSH session. The default API key is the empty field; if you set one in Settings → Auth & Info, replace '' with it. --bare drops Claude Code’s system prompt to ~1,795 tokens, and --dangerously-skip-permissions bypasses interactive permission prompts that don’t make sense in an automated pipeline.
Benchmark on real hardware
Bench → Performance runs tests on your actual hardware. The panel covers prefill at several prompt sizes (pp1024, pp4096, pp8192, pp16384, pp32768, pp65536, pp131072, pp200000) and continuous batching at 2x, 4x and 8x concurrency. Submit your results to the public oMLX leaderboard[4] from My Submissions to compare against other machines on the same profile.
Reference numbers measured on M5 Max 40-core with 128 GB (not extrapolated: the omlx.ai leaderboard[4] already has M5 Max submissions, and vLLM’s independent TurboQuant study published 11 May 2026[2] confirms the figures for the large dense models):
- Qwen 3.6 35B-A3B 8-bit (MoE, 3B active): 65-80 tok/s on decode at short context. The model that most changes day-to-day use on this machine. Live benchmarks from this setup:
| Test | TTFT | Decode TPS | E2E | Peak Mem |
|---|---|---|---|---|
| pp1024/tg128 | 577ms | 72.4 tok/s | 2.35s | 38.5 GB |
| pp4096/tg128 | 1,293ms | 83.1 tok/s | 2.83s | 36.2 GB |
| pp8192/tg128 | 2,995ms | 82.1 tok/s | 4.55s | 36.5 GB |
| pp32768/tg128 | 13,785ms | 15.2 tok/s | 22.18s | 40.9 GB |
Continuous batching (pp1024 / tg128):
| Batch | Decode TPS | Speedup |
|---|---|---|
| 1x (baseline) | 72.4 tok/s | 1.00x |
| 2x | 87.1 tok/s | 1.20x |
| 4x | 123.8 tok/s | 1.71x |
| 8x | 237.7 tok/s | 3.28x |
- Llama 3.3 70B 4-bit: 14-18 tok/s on decode.
- Mistral Large 2 123B 4-bit with TurboQuant 3.5-bit on KV cache: 8-11 tok/s on decode, and the number that matters at 128k context: peak memory ~74 GB (FP16 KV blows past 128 GB). dasroot.net’s long-context M5 Max experiment[5] documents the same peaks for the 104B dense model.
- gpt-oss-20b MXFP4-Q4 on M5 Max 40c per the public oMLX benchmark submission[6] lands around 100 tok/s on decode.
The 4.41x KV-cache compression from TurboQuant (measured by vLLM in May 2026) is what separates “I have 128k context but it does not fit” from “I have it and can load two other models alongside it.” At 4-bit and 3.5-bit, quality stays close to full precision; at 3-bit you start to feel it in code and long-form reasoning.
End-to-end verification
A curl call to the OpenAI-compatible API to confirm the server is alive and a model responds:
curl http://127.0.0.1:8000/v1/chat/completions
-H "Authorization: Bearer <your_api_key>"
-H "Content-Type: application/json"
-d '{
"model": "Qwen3-Coder-30B-A3B-Instruct-mlx-8bit",
"messages": [{"role":"user","content":"Hello from oMLX"}]
}'
And from Claude Code, once you have exported the variables from the previous section:
claude --print "Are you running locally?"
The reply should come back from local without touching api.anthropic.com. To confirm at the network level, open Activity Monitor → Network, filter by the claude process and check that the outbound connection is against 127.0.0.1:8000.
Sources and further reading
- Diego R. Baquero, “Running Claude Code with a local LLM”[3]: the tested configuration recipe this post’s settings are based on (TurboQuant 3.5-bit, 64k context, attribution off, Qwen 3.6 35B-A3B models).
- A First Comprehensive Study of TurboQuant, vLLM blog, 11 May 2026[2]: independent analysis confirming 3.5-bit matches full-precision quality.
- omlx.ai/benchmarks[4]: public leaderboard with real submissions from M5 Max and other machines.
- Maxing Out M5 Max Context Windows: Memory Fragmentation and TurboQuant Benchmarks (dasroot.net, April 2026)[5]: the other detailed experiment on long-context M5 Max with TurboQuant.
- Repositories: jundot/omlx[7], ml-explore/mlx[8], ml-explore/mlx-lm[9], huggingface.co/mlx-community[10], huggingface.co/unsloth[11].
For a cross-platform alternative outside Apple Silicon, the Ollama local LLM guide covers the model catalogue and OpenAI-compatible API. To wire the local endpoint into an agent, the Anthropic SDK tutorial and the MCP multi-vendor patterns already talk to this same format with no code changes.
- GitHub Releases
- vLLM’s independent analysis published 11 May 2026
- Diego R. Baquero’s gist
- public oMLX leaderboard
- dasroot.net’s long-context M5 Max experiment
- gpt-oss-20b MXFP4-Q4 on M5 Max 40c per the public oMLX benchmark submission
- jundot/omlx
- ml-explore/mlx
- ml-explore/mlx-lm
- huggingface.co/mlx-community
- huggingface.co/unsloth



