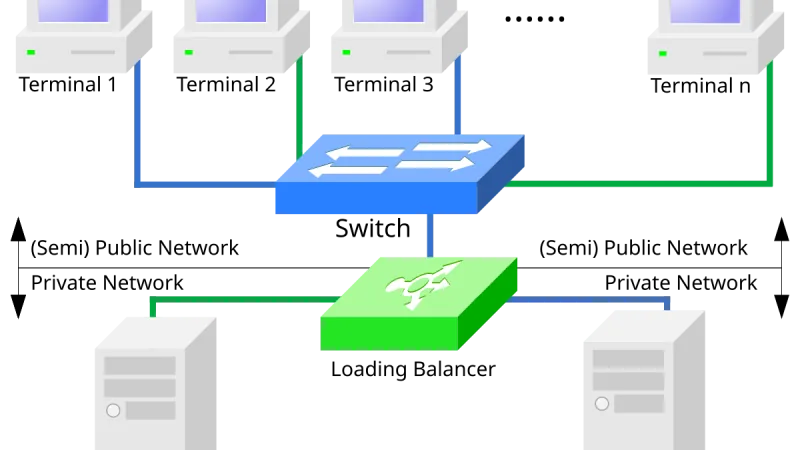
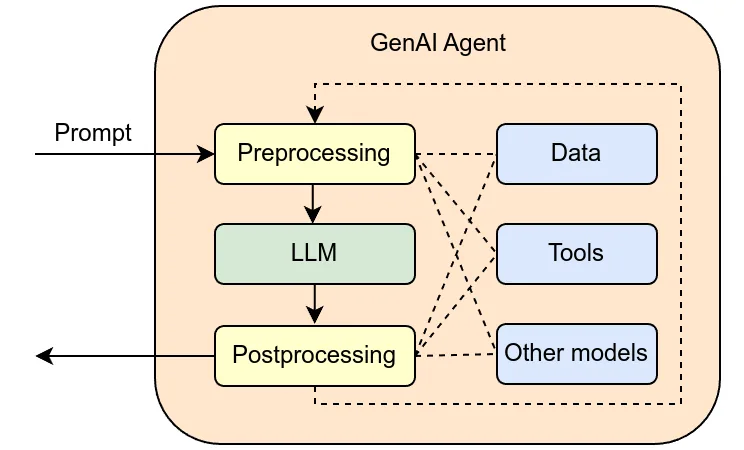
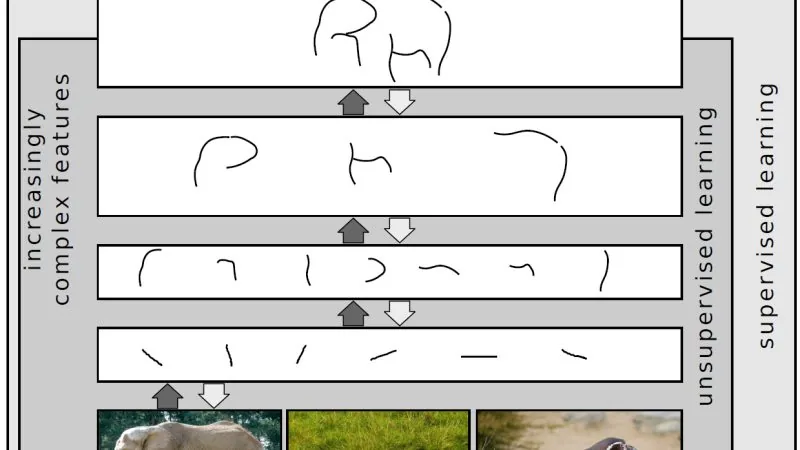
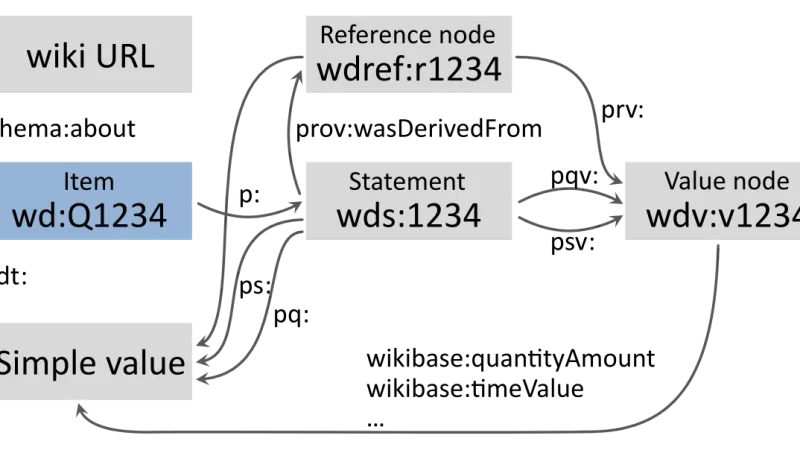
Receta probada en mayo de 2026: oMLX 0.3.8 en Mac M5 Max con 128 GB, TurboQuant a 3,5-bit, stack Qwen 3.6 35B-A3B, wiring para Claude Code y benchmarks reales.
La idea de que la UI se genere sobre la marcha en lugar de ser prediseñada llegó a producción en 2025. Tras un año de casos reales, el balance es más matizado que el entusiasmo inicial.
Direct Preference Optimization y sus primas han desplazado a RLHF como alineamiento preferido en gran parte del ecosistema. Este es el estado práctico del campo en 2026.
Los datos sintéticos han dejado de ser sustituto precario de datos reales para convertirse en componente central del entrenamiento moderno. Estos son los patrones probados y los que todavía fallan.
Tres años después del boom inicial, el RAG en producción ha convergido en patrones híbridos que combinan búsqueda densa, léxica y reranking. Estos son los que sobreviven al paso del tiempo.
La primera factura de un agente en producción suele ser más alta de lo que el equipo esperaba. Este artículo recoge las palancas reales para controlar el coste sin sacrificar calidad.
El red teaming de modelos de lenguaje ha pasado de actividad esotérica a práctica obligatoria. Con OWASP Agentic Top 10 y CSA Agentic AI Red Teaming Guide convergiendo en un vocabulario común, este es el manual operativo que cualquier equipo que despliegue agentes necesita tener.
Prompt engineering ha pasado de ser una colección de trucos virales a una disciplina con patrones reproducibles, librerías dedicadas y herramientas de observabilidad.
La factura de IA en las empresas ha dejado de ser anecdótica. Entre tokens de modelos frontera, GPUs reservadas que nadie usa y pipelines RAG con cachés mal configuradas, muchos equipos pagan diez veces lo que deberían. Guía de FinOps específico para IA sin relatos promocionales.
Los grafos de conocimiento llevaban dos décadas esperando su momento. Con los LLM como puente entre texto y ontología, y el patrón GraphRAG ya maduro, la tecnología vuelve al primer plano. Toca revisar por qué ahora sí encaja y dónde conviene usarla.
Los modelos grandes de lenguaje llevan dos años prometiendo documentar código, APIs y arquitecturas sin esfuerzo. Después de ver docenas de proyectos intentarlo, hay patrones claros de dónde funciona y dónde acaba siendo una deuda más.
Los frameworks de guardrails prometen filtrar entradas y salidas de modelos de lenguaje para bloquear fugas de datos, contenido dañino o alucinaciones. Tras evaluar cuatro de los más populares en producción, repaso qué hacen realmente, qué coste en latencia y factura añaden y cuándo compensan frente a controles más simples.
Los agentes que encadenan llamadas a modelos, herramientas y memoria son difíciles de depurar sin una instrumentación pensada para ellos. Después de un año largo operando agentes en producción, repaso qué hay que medir primero, qué estándares están consolidándose y qué errores caros evita tener trazas bien hechas desde el inicio.
Un proxy con caché delante de un modelo de lenguaje puede reducir la factura de tokens de forma significativa, pero introduce riesgos sutiles si el diseño no es cuidadoso. Qué tipos de caché funcionan en producción, dónde están las trampas habituales y cómo integrarlos sin degradar la experiencia.
Un enrutador de inferencia decide qué modelo atiende cada petición en función de coste, latencia y complejidad. Bien diseñados reducen la factura de tokens sin que el usuario perciba degradación; mal diseñados introducen fallos sutiles difíciles de depurar.
Probar sistemas que incluyen modelos de lenguaje rompe la primera regla del testing: la misma entrada da la misma salida. Analizo las estrategias que han funcionado tras un año largo integrando IA en productos reales, por qué los tests deterministas tradicionales no bastan y cómo plantear un cinturón de pruebas que capture regresiones sin bloquearse en la varianza.
El término Agent OS lleva un año ganando tracción entre investigación y producto. Describe una capa que va más allá de una biblioteca de agentes: planificador, gestión de contexto, memoria persistente y aislamiento. Una lectura del estado real de ese concepto.
Model Context Protocol cumple diez meses desde su anuncio de Anthropic y ya no es una propuesta: hay cientos de servidores, implementaciones cruzadas entre proveedores y un registro público. Repaso de qué ha funcionado, qué sigue flojo y por qué 2025 marca el paso de curiosidad a infraestructura básica.
Tras meses de rumores, OpenAI publicó GPT-5 a principios de agosto. Las primeras semanas de uso real dejan una imagen menos espectacular que el marketing y más útil que lo que muchos esperaban. Vale la pena separar lo nuevo de lo incremental.
Los modelos pequeños de lenguaje se han vuelto útiles de verdad. Phi-3.5, Gemma 2 o Llama 3.2 caben en dispositivos modestos y resuelven tareas acotadas sin salir a la nube. Repaso de dónde encajan en planta y cuándo compensa saltarse el modelo grande.
El RAG de 2023 era búsqueda vectorial con un LLM detrás. El de 2025 es un sistema híbrido que combina vectores, búsqueda léxica y grafos de conocimiento. Qué ha cambiado, dónde funciona cada pieza y qué decisiones marcan la diferencia entre un RAG útil y uno decepcionante.
Google publicó Gemini 2.5 Pro en vista previa en marzo y la versión general llegó en junio. El salto respecto a Gemini 2.0 no está solo en puntuaciones sino en dos frentes prácticos: ventana de contexto utilizable en serio y multimodalidad que deja de ser demostración para convertirse en herramienta.
Anthropic presentó Claude Opus 4 y Claude Sonnet 4 el 22 de mayo de 2025, el primer salto grande de nomenclatura desde la serie 3.5. Un mes de uso real en código, documentación técnica y agentes para separar lo que ha mejorado de lo que sigue igual.
Durante una década los grafos de conocimiento fueron una idea académica con pocos casos vivos. Los LLM han cambiado esa ecuación: ahora sirven para anclar respuestas, auditar razonamiento y sostener agentes sin alucinar.
6 min2144,5
Usamos cookies propias y de terceros para analizar el tráfico del sitio. Puedes aceptarlas, rechazarlas o configurar tu elección.
Más información
Preferencias de cookies
NecesariasImprescindibles para el funcionamiento del sitio. Siempre activas.
AnalíticasNos ayudan a entender cómo se usa el sitio (Google Analytics).