Code Interpreter de OpenAI: análisis de datos conversacional
Cómo Code Interpreter convierte ChatGPT en un analista de datos capaz de ejecutar Python, manipular ficheros y generar gráficos sobre la marcha.
Categoría
Inteligencia artificial sin hype: modelos, agentes y casos de uso que funcionan en producción.
Cómo Code Interpreter convierte ChatGPT en un analista de datos capaz de ejecutar Python, manipular ficheros y generar gráficos sobre la marcha.
DINOv2 de Meta AI entrena modelos de visión por computadora sin etiquetas humanas, con resultados que superan a modelos supervisados en tareas de clasificación, segmentación y profundidad.
Cerebras-GPT libera 7 modelos de lenguaje open-source entrenados sobre hardware especializado. Qué los diferencia, dónde descargarlos y para qué son útiles.
Qdrant, Pinecone y Weaviate comparados en búsqueda semántica, escalabilidad y modelo de despliegue. Cuál elegir según tu caso de uso.
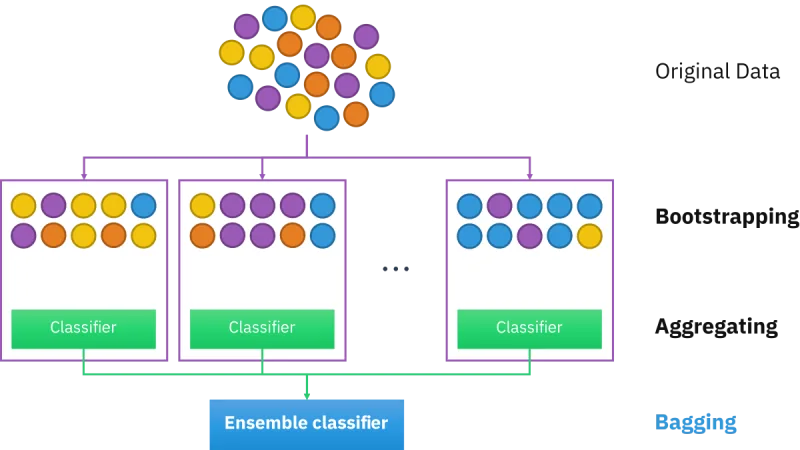
Bagging, boosting y stacking: cómo los métodos de ensamble combinan modelos débiles para construir predictores más robustos y por qué dominan en tabular data.
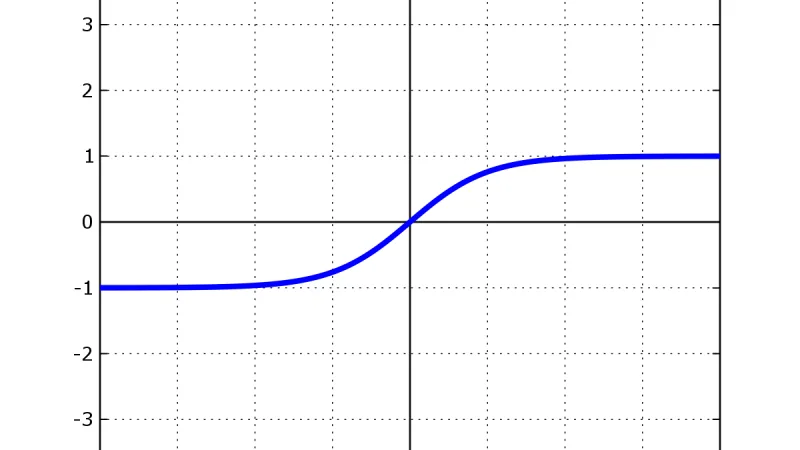
La tangente hiperbólica (tanh) produce salidas simétricas entre -1 y 1, lo que la convierte en una función de activación más estable que la sigmoide para capas ocultas.
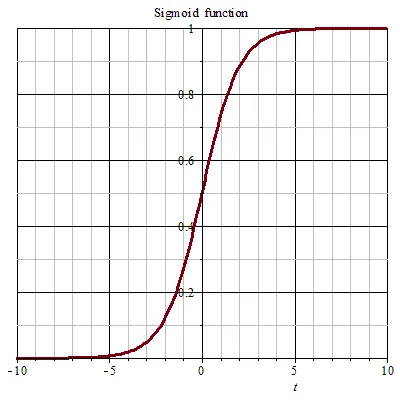
La función sigmoide comprime cualquier valor de entrada en el rango (0, 1), lo que la convierte en la función de activación natural para modelar probabilidades en redes neuronales.
La función Softmax convierte vectores de salida de una red neuronal en distribuciones de probabilidad. Es el estándar para clasificación multiclase y el fundamento matemático de los modelos de lenguaje.
Leaky ReLU resuelve el problema de la neurona muerta de ReLU estándar al permitir un gradiente pequeño en la región negativa, mejorando el entrenamiento en redes profundas.
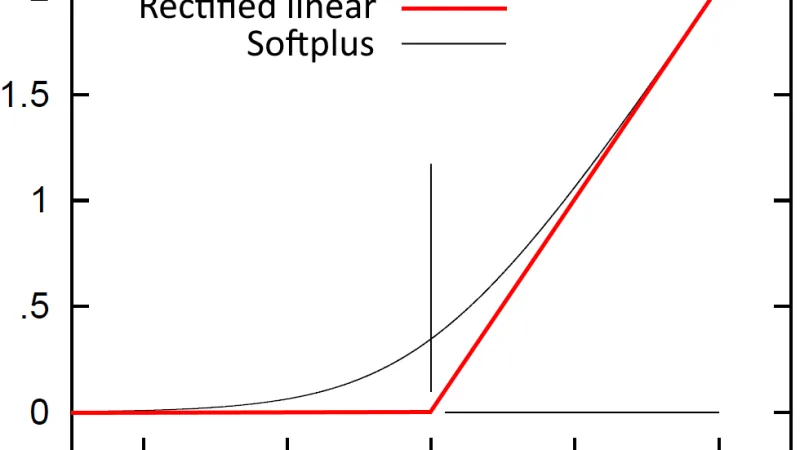
ReLU es la función de activación más utilizada en redes neuronales profundas: simple, eficiente y resistente al desvanecimiento del gradiente que lastra a la sigmoide.
La función escalón o de Heaviside es la función de activación más simple de una red neuronal: convierte cualquier entrada en una salida binaria 0 o 1.
La función lineal es la función de activación más simple en redes neuronales. Útil para regresión, pero con limitaciones críticas para capas ocultas: no introduce no linealidad.