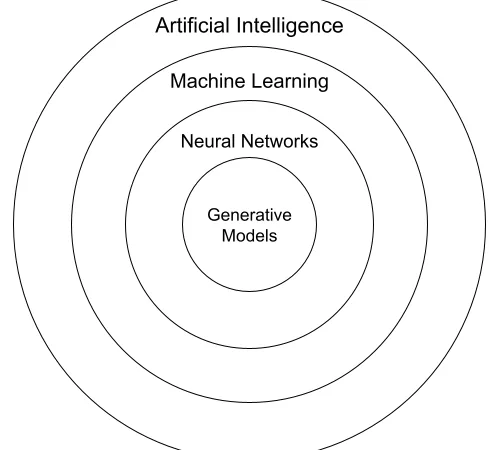
Artificial Intelligence
Claude 2: Anthropic’s Alternative to GPT-4
Claude 2 ofrece contexto largo (100K tokens) y un enfoque distinto a la seguridad. Cómo se compara realmente con GPT-4 en uso práctico.
Category
AI without the hype: models, agents and use cases that work in production.
Claude 2 ofrece contexto largo (100K tokens) y un enfoque distinto a la seguridad. Cómo se compara realmente con GPT-4 en uso práctico.
Las bases vectoriales han pasado de ser experimentales a base de productos LLM. Comparativa pragmática entre las tres opciones más usadas en 2023.
Con cuantización y llama.cpp se puede ejecutar Llama 2 7B/13B en un portátil moderno. Cómo funciona y qué calidad esperar realmente.
pgvector convierte PostgreSQL en una base vectorial competente. Por qué la búsqueda semántica necesita índices especializados y cuándo basta con extender Postgres.
LangChain unifica la construcción de aplicaciones con LLM: prompts, retrievers, agentes y memoria. Cuándo ayuda y cuándo añade complejidad innecesaria.
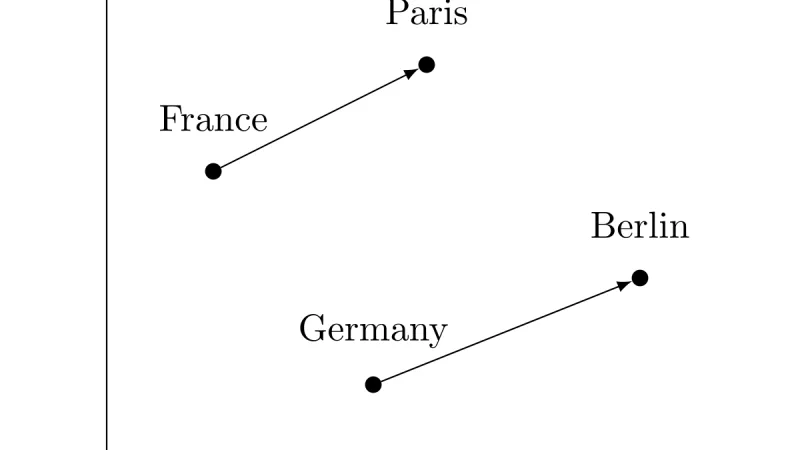
Los embeddings convierten texto en vectores con significado semántico. Cómo se generan, qué modelos elegir y para qué casos sirven realmente.
Function calling convierte el LLM en un componente que devuelve datos estructurados. Cómo funciona, casos de uso reales y errores comunes.
Chroma es la opción más simple para empezar con embeddings y búsqueda semántica. Cuándo brilla, cuándo se queda corta y cómo desplegarla.
Midjourney v5 marca un salto de calidad visual en generación de imágenes. Qué cambia y cómo encaja frente a Stable Diffusion XL y DALL-E 3.
EU AI Act, executive order de EEUU y el Reino Unido preparan su marco. Panorama regulatorio de IA en septiembre 2023.
Ollama hace trivial ejecutar modelos como Llama 2 o Mistral en local. Instalación en macOS, Linux y Windows, y una lectura honesta de qué se puede y qué no.
El mantenimiento predictivo industrial rara vez necesita deep learning. Modelos clásicos bien diseñados resuelven el 80% de los casos.
Cinco meses después del lanzamiento de GPT-4, es momento de separar capacidades reales de hype. Dónde destaca y dónde sigue fallando.
Meta liberó LLaMA 2 con licencia comercial y esto cambia el panorama de modelos de lenguaje abiertos. Qué implica para equipos que construyen con IA.
Google lanzó Bard con PaLM 2 como respuesta directa a ChatGPT. Análisis de capacidades, comparativa con GPT-4 y estrategia de integración con su ecosistema.
Fine-tuning sigue siendo caro y operativamente complejo. Guía para decidir entre RAG, prompt engineering y entrenamiento propio.
Stable Diffusion XL marca un salto en calidad de imagen generada bajo licencia abierta. Qué cambia frente a SD 1.5/2.1, requisitos de hardware y cuándo elegir SDXL sobre Midjourney o DALL-E 3.
A tres meses del lanzamiento de los plugins de ChatGPT, el ecosistema muestra potencial real en consulta de datos en vivo y claras fricciones en orquestación y transacciones.
Cómo Code Interpreter convierte ChatGPT en un analista de datos capaz de ejecutar Python, manipular ficheros y generar gráficos sobre la marcha.
DINOv2 de Meta AI entrena modelos de visión por computadora sin etiquetas humanas, con resultados que superan a modelos supervisados en tareas de clasificación, segmentación y profundidad.
Cerebras-GPT libera 7 modelos de lenguaje open-source entrenados sobre hardware especializado. Qué los diferencia, dónde descargarlos y para qué son útiles.
Qdrant, Pinecone y Weaviate comparados en búsqueda semántica, escalabilidad y modelo de despliegue. Cuál elegir según tu caso de uso.
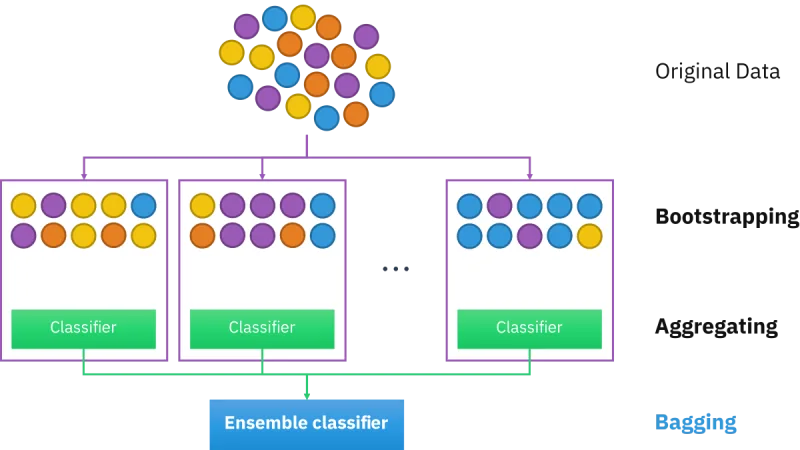
Bagging, boosting y stacking: cómo los métodos de ensamble combinan modelos débiles para construir predictores más robustos y por qué dominan en tabular data.
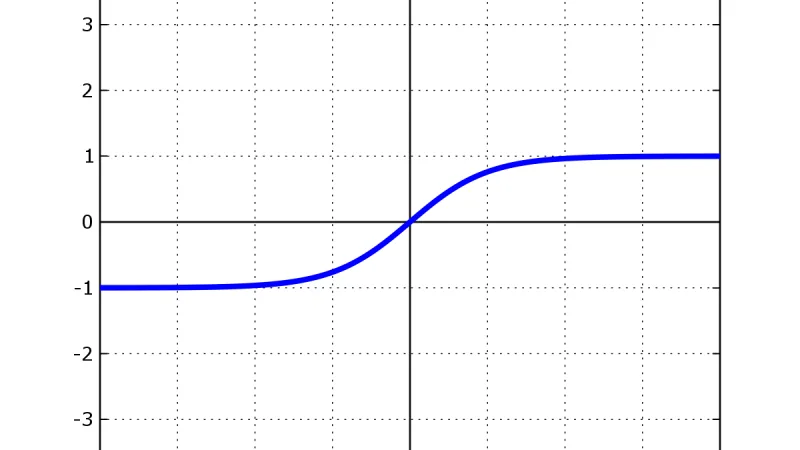
La tangente hiperbólica (tanh) produce salidas simétricas entre -1 y 1, lo que la convierte en una función de activación más estable que la sigmoide para capas ocultas.
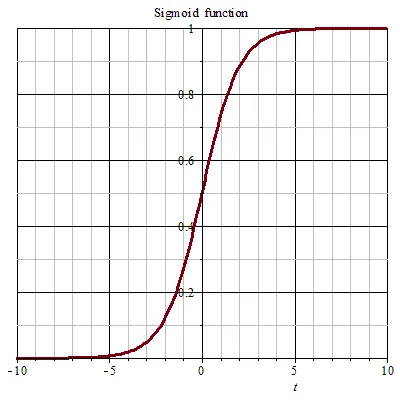
La función sigmoide comprime cualquier valor de entrada en el rango (0, 1), lo que la convierte en la función de activación natural para modelar probabilidades en redes neuronales.
La función Softmax convierte vectores de salida de una red neuronal en distribuciones de probabilidad. Es el estándar para clasificación multiclase y el fundamento matemático de los modelos de lenguaje.
Leaky ReLU resuelve el problema de la neurona muerta de ReLU estándar al permitir un gradiente pequeño en la región negativa, mejorando el entrenamiento en redes profundas.
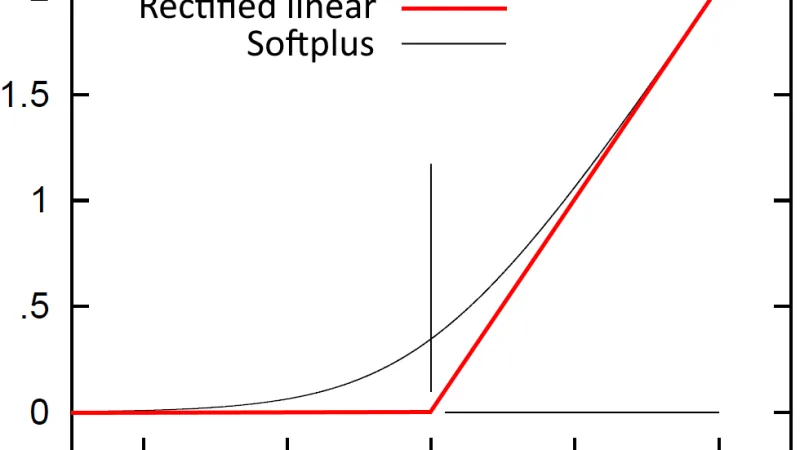
ReLU es la función de activación más utilizada en redes neuronales profundas: simple, eficiente y resistente al desvanecimiento del gradiente que lastra a la sigmoide.
La función escalón o de Heaviside es la función de activación más simple de una red neuronal: convierte cualquier entrada en una salida binaria 0 o 1.
La función lineal es la función de activación más simple en redes neuronales. Útil para regresión, pero con limitaciones críticas para capas ocultas: no introduce no linealidad.
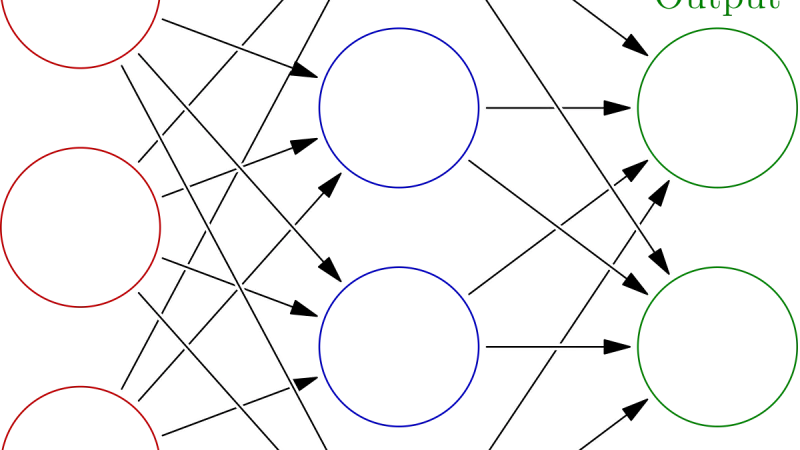
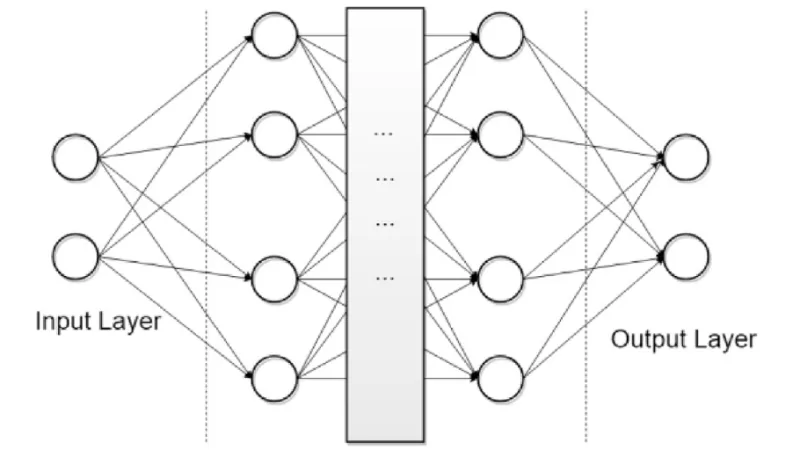
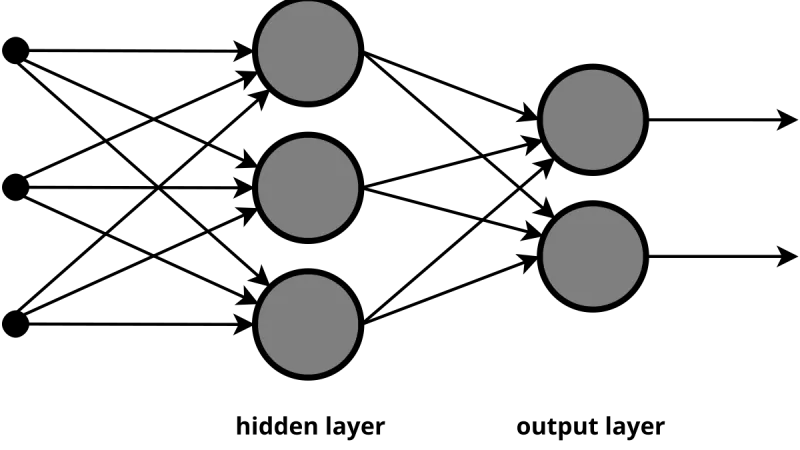
La red neuronal totalmente conectada o densa es el bloque fundamental del aprendizaje profundo: cada neurona se conecta con todas las de la capa anterior y posterior.
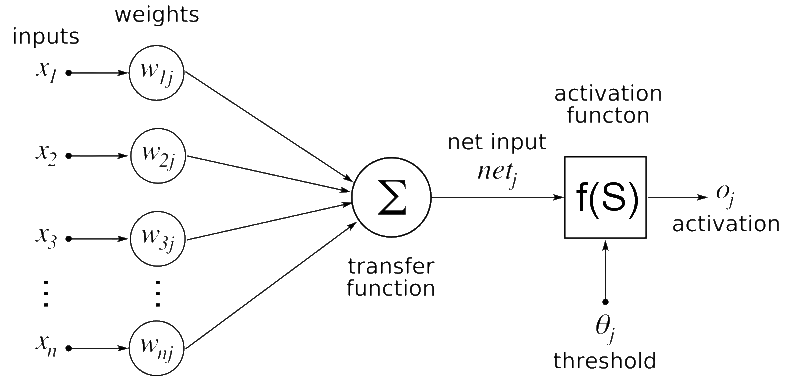
Cómo se representan matemáticamente las entradas, pesos y funciones de activación en una red neuronal artificial, y cómo el algoritmo de retropropagación ajusta esos pesos durante el entrenamiento.
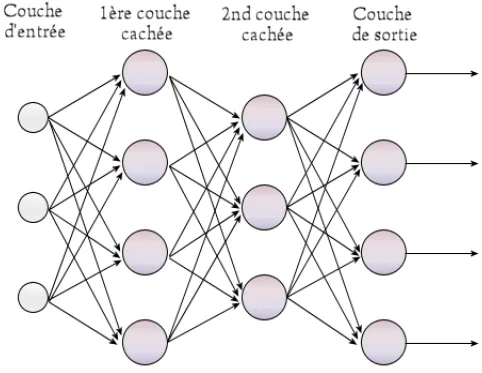
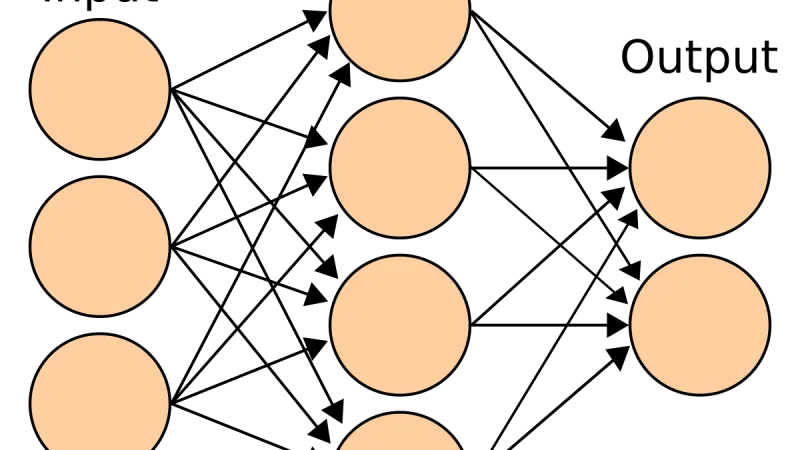
Cómo funcionan las redes neuronales multicapa, qué las hace tan poderosas y por qué el deep learning depende de ellas para resolver problemas complejos.
Cómo los dataframes y los pipelines de Apache Spark permiten procesar grandes volúmenes de datos de forma eficiente, distribuida y optimizable en clústeres.
LazyPredict evalúa automáticamente decenas de modelos de scikit-learn sobre tu dataset en segundos. Aprende a usarlo para clasificación y regresión con ejemplos de código reales.
La IA transforma el ciclo de ventas B2B: desde la identificación de oportunidades hasta el cierre. Qué herramientas funcionan, qué métricas mejorar y qué errores evitar.
ChatGPT 4 combina procesamiento del lenguaje natural avanzado con aprendizaje profundo para ofrecer conversaciones más naturales y personalizadas. Qué cambia y qué implica para las empresas.
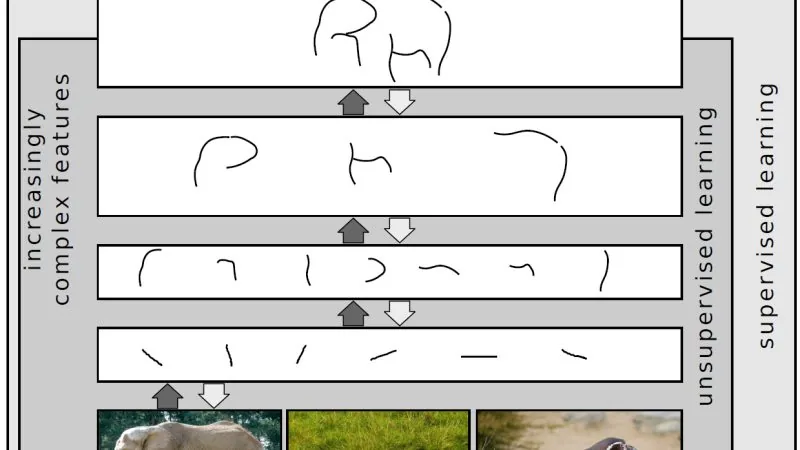
La transferencia de aprendizaje permite reutilizar modelos entrenados en grandes conjuntos de datos para resolver tareas nuevas con mucho menos datos y tiempo de cómputo. Cómo funciona y cuándo usarla.
El aprendizaje de máquina adversarial estudia los ataques contra sistemas de IA y los mecanismos de defensa para hacerlos robustos frente a manipulaciones maliciosas.
El aprendizaje federado permite entrenar modelos de IA de forma colaborativa sin compartir datos privados, mediante el envío de gradientes en lugar de datos en bruto.
Los sistemas de recomendación son el motor invisible de Netflix, Amazon y Spotify. Cómo funciona el filtrado colaborativo, qué variantes existen y cómo se evalúa su eficacia.
La IA explicable (XAI) responde a una pregunta crítica: ¿por qué el modelo tomó esa decisión? Una exploración de métodos como LIME y SHAP y su aplicación en salud, justicia y comercio.
El aprendizaje por refuerzo enseña a los sistemas de IA a tomar decisiones óptimas mediante recompensas y penalizaciones. Componentes, aplicaciones y limitaciones de esta técnica clave.
La robótica y la automatización inteligente combinan IA, aprendizaje automático y robots físicos para transformar la fabricación, la logística y la sanidad.
La visión computarizada permite extraer información útil de imágenes digitales mediante redes neuronales, segmentación y detección de patrones. Sus aplicaciones cubren industria, medicina y transporte.
El procesamiento del lenguaje natural (NLP) permite a las máquinas entender e interpretar el idioma humano. Repaso a sus aplicaciones, evolución y hacia dónde apunta.
Cómo las redes neuronales profundas han transformado el reconocimiento de voz, la visión computarizada y el procesamiento del lenguaje natural.